TP2 🧮 Analyse de données
Une vidéo expliquant en détail le TP et fournissant quelques conseils est disponible en bas de page.
Les données sont partout autour de nous. Savoir les analyser et en tirer des conclusions est une compétence essentielle dans de nombreux domaines, en particulier en science.
Dans ce TP, vous allez choisir un ensemble de données réelles, les analyser à l'aide de Python et produire des visualisations pour illustrer vos découvertes.
À la fin de ce travail, vous serez capable de :
- Lire et traiter des fichiers CSV avec Pandas
- Créer des visualisations de données avec Matplotlib
- Interpréter des données scientifiques réelles
- Écrire dans un fichier texte un rapport
Pour faire ce TP, vous devez créer un nouveau projet PyCharm et utiliser un répertoire GitHub dès le début.
- Si votre enseignant utilise GitHub Classroom, utilisez le répertoire créé par votre enseignant.
- Si votre enseignant n'utilise pas GitHub Classroom, créez votre propre répertoire et partagez-lui l'accès en lecture.
❗🤖 👀 🚫
Si votre travail est suspecté de plagiat (code copié d'un(e) autre étudiant(e), code généré par IA, notions non abordées en classe, etc.), deux choses peuvent se produire :
- Le plagiat est prouvé par nos outils : note de 0, automatiquement.
- Le plagiat est plutôt évident, mais une validation est requise : vous serez convoqué(e) au bureau de votre enseignant(e). Vous devrez répondre à certaines questions pour prouver que vous comprenez et maîtrisez le code qui a été utilisé. Si vous ne réussissez pas à répondre à certaines questions, vous aurez la note de 0 (si vous ne comprenez pas votre propre code, c'est que vous avez plagié, d'une manière ou d'une autre).
- Suivre le lien donné pour chercher, trouver et télécharger le fichier CSV de données approprié en lien avec le projet.
- Écrire un script Python qui lit le fichier CSV, analyse les données et produit :
- des figures (en format PNG) en utilisant les bibliothèques Pandas et Matplotlib.
- un fichier texte contenant les réponses à des questions d'analyse.
Votre projet doit contenir exactement les 2 scripts Python mentionnés ci-dessous ainsi que le fichier .gitignore et rien d'autre (ne laissez traîner aucun script inutile).
tp2/
├── autocorrection.py # ce fichier vous est fourni et sert à l'autocorrection de votre travail
├── analyse.py # vous devez créer ce script, il va contenir le code de votre TP
└── .gitignore # indique les fichiers que Git doit omettre lors de la création d'un commit
Téléchargez le fichier autocorrection.py et le fichier .gitignore et placez-les dans votre projet.
Si le fichier .gitignore est téléchargé sous un autre nom (ex : gitignore.txt), renommez-le en .gitignore (sans extension et avec le point au début).
Tous les autres fichiers utilisés (CSV) ou produits (PNG, TXT) par votre programme ne doivent pas être commités dans votre dépôt Git.
Concernant la structure du fichier analyse.py, il doit :
- posséder exactement les 11 fonctions demandées, pas 1 de plus ou de moins!
- ne contenir aucun code dans la portée globale, tout code doit être dans une fonction ;
- respecter toutes les directives et contraintes, elles seront mentionnées au fur et à mesure.
GitHub est avant tout une plateforme conçue pour héberger des fichiers légers contenant du code source.
Par principe, certains éléments ne doivent jamais figurer dans un dépôt Git :
- Les fichiers volumineux : ils ralentissent les opérations de clonage et de mise à jour.
- Les fichiers de configuration d'IDE : par exemple, le dossier
.ideade PyCharm, qui est propre à votre environnement de travail local. - Les fichiers générés : tout ce qui peut être produit automatiquement par l'exécution de votre programme.
En suivant ces principes, le fichier CSV que vous devrez télécharger est particulièrement massif et ne devrait pas être sauvegardé sur GitHub. Vous devrez donc retélécharger le fichier CSV et le replacer dans votre dossier de projet à chaque fois que vous changerez de poste dans les laboratoires du Cégep. Concernant les fichiers TXT et PNG, ils sont dans le cadre de ce TP le résultat direct de l'exécution de votre code, il est donc inutile de les versionner : nous préférons que votre dépôt ne contienne que la "recette" (votre code) et non les produits finis.
Le fichier .gitignore sert à quoi? Il indique à Git d'ignorer (de ne pas sauvegarder dans le répertoire) certains fichiers ou dossiers en fonction de modèles (patterns) définis à l'intérieur.
Dans le cadre de ce projet, il a été configuré pour exclure automatiquement les fichiers CSV, PNG et TXT de vos commits.
- Au moins 5 commits de tailles comparables (il n'y a pas un commit avec tout dedans et les autres vides)
- Les commits décrivent l'avancement du projet dans un français sans faute (voir instructions)
- Chaque fonction doit être documentée à l'aide d'un docstring dans un français sans faute.
Bien qu'Excel soit l'outil par défaut pour lire des fichiers CSV, il n'est pas adapté aux jeux de données massifs scientifiques que nous utilisons.
- Affichage incomplet : Au-delà d'un certain seuil (environ 1 million de lignes), Excel tronque les données et n'affiche pas la totalité du fichier.
- Risque d'altération : Excel a tendance à reformater automatiquement les données, ce qui peut corrompre l'intégrité de votre fichier CSV.
Conseil : Évitez d'ouvrir le fichier CSV avec Excel!
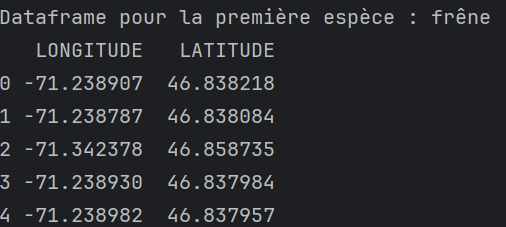
- Commencez par explorer les données pour comprendre leur structure et leur contenu, en utilisant des fonctions comme
head(),info()etdescribe()de Pandas.
🌳 Analyse des arbres répertoriés dans la Ville de Québec
- La Ville de Québec a répertorié les arbres situés sur son territoire.
L'objectif de ce projet est d'analyser ces données pour comprendre la répartition des espèces d'arbres, leur taille, etc.
- Données Québec : Arbres répertoriés dans la Ville de Québec
- Téléchargez le fichier CSV.
Écrivez du code pour répondre aux questions suivantes (écrivez une fonction par question) :
-
#1 - Quelles sont les variables présentes dans le jeu de données?
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA1et retourner uneliste de string. -
#2 - Le nom de la topographie où se trouve l'arbre avec le tronc le plus gros?
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA2et retourner unestring. -
#3 - Combien dénombre-t-on d'espèces différentes chez les feuillus et les conifères?
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA3et retourner untuplecomposé du nombre de feuillus suivi du nombre de conifère. -
#4 - Quelles sont les espèces d'arbres (en français) que l'on retrouve dans le
Parc Aimée-Miville? Trier les alphabétiquement (Il est normal que les mots accentués apparaissent à la fin).
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA4et retourner uneliste de string. -
#5 - De quelle espèce est l'arbre avec le tronc le plus gros? (en français)
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA5et retourner unestring. -
#6 - Quel est le diamètre moyen du tronc des feuillus à l'Université Laval? Des conifères?
La fonction doit être la seule à posséder dans sa docstring l'abréviationQA6et retourner undictionnaireavec ces 2 clés :diametre_feuillusetdiametre_coniferes.
CONTRAINTES À RESPECTER
Concernant ces fonctions, elles doivent :
- Pouvoir être appelées sans paramètre;
- Retourner le résultat dans le format indiqué;
- Chacune faire appel à la fonction
pd.read_csv(); - Chacune nettoyer, si nécessaire, les données en fonction des besoins de la question;
- Posséder l'abréviation demandée dans les docstrings (nécessaire pour l'autocorrecteur);
- N’utilisez aucune boucle (
for,while) ni aucune liste de compréhension;
Aucune de ces fonctions ne doit appeler la fonction print()!
Ici, on joue selon les règles du réel : les réponses ne tombent pas du ciel.
Pour savoir si vous avez visé juste, fiez-vous au script d'autocorrection.
Développez une fonction dont le rôle est d'enregistrer toutes les questions d'analyse et leurs réponses respectives dans un seul fichier texte.
- Nom du fichier : Le fichier doit impérativement s'appeler
sommaire.txt. - Contenu : Il doit inclure à la fois :
- l'énoncé de la question (ex : « Quel est... ? ») et la réponse obtenue (ex : « 52 »).
- Les réponses ne doivent contenir ni accolades
{}, ni crochets[], ni parenthèses(), ni guillemets.
- Documentation : La docstring de la fonction doit obligatoirement inclure l'abréviation
QASommaire. - Structure : Cette fonction doit appeler les six fonctions développées précédemment pour récupérer les données nécessaires.
- Clarté : Le contenu du fichier doit être organisé de manière claire et lisible, avec une question suivie de sa réponse, puis la question suivante, etc.
Cette fonction ne prend aucun paramètre et ne retourne aucune valeur.
Vous devez produire 4 figures, chacune nécessitant la création d'une fonction distincte (total de 4 fonctions).
Chaque fonction doit :
- Utiliser
pd.read_csv()pour charger les données; - Effectuer le nettoyage de données requis par la problématique lorsque vous le jugez nécessaire;
- Préparer un DataFrame contenant exclusivement les colonnes et les lignes nécessaires à la figure;
- Générer le graphique demandé à l'aide de matplotlib à l'aide des données du DataFrame;
- Exporter le résultat final au format
.png; - S’exécuter sans paramètre;
- Ne rien retourner.
Il est IMPOSSIBLE de créer un graphique à partir d'un DataFrame avec les mauvaises données.
Assurez-vous que le DataFrame contient les bonnes données avant de débuter la réalisation du graphique!
Un aperçu du contenu des DataFrames est généralement mis à votre disposition, profitez-en!
LES 4 FIGURES À PRODUIRE
- Figure 1
- Figure 2
- Figure 3
- Figure 4
Un graphique montrant la localisation de tous les arbres de la Ville de Québec.
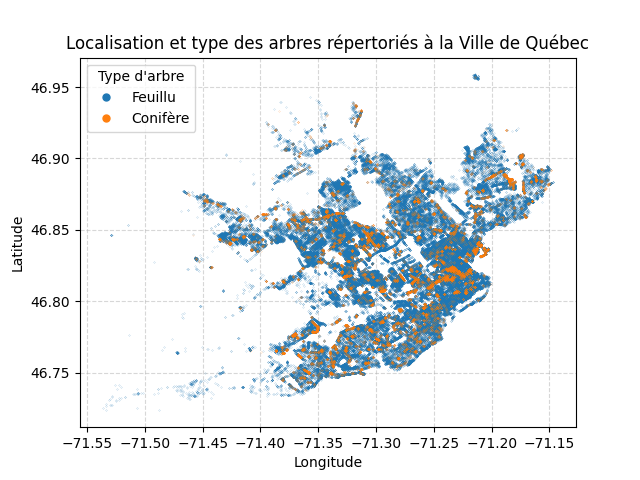
- L'image générée doit se nommée
figure1.png;
ASTUCES
- Retirer les lignes du DataFrame pour lesquelles il n'y a pas de valeur pour la colonne
TYPE_ARBRE; - Récupérer une liste des types d'arbres à partir du DataFrame;
- Pour chacun des types d'arbres de la liste :
- Récupérez les données pour ce type d'arbre;
- Ajoutez-les au graphique à l'aide d'un nuage de points avec une taille de marqueur de
0.1;
- La légende doit avoir le titre Type d'arbre et avoir une mise à l'échelle des marqueurs de
50.
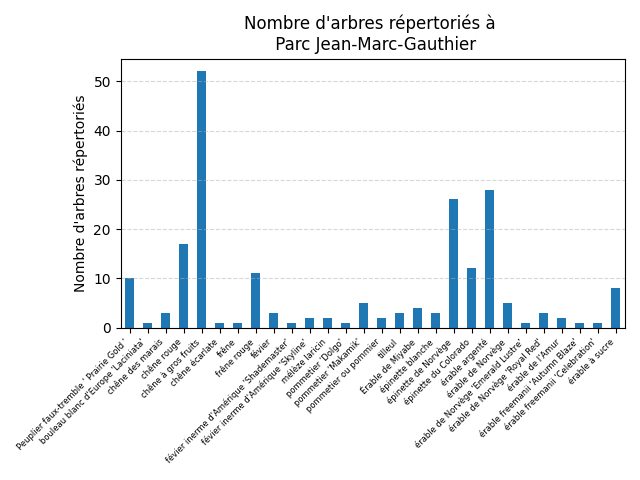
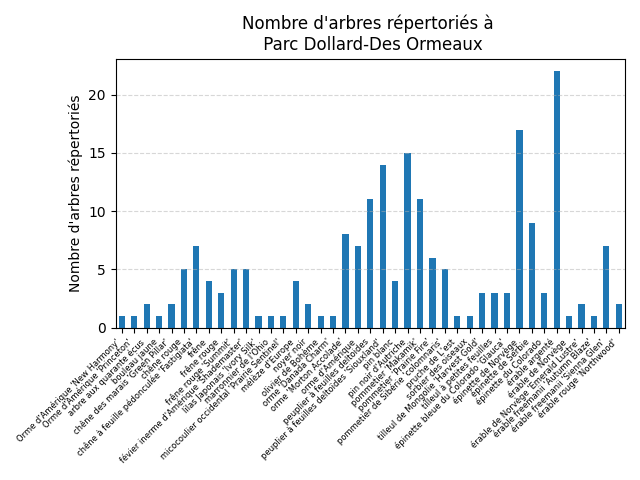
Un graphique montrant le nombre d'arbres par espèce répertorés dans un parc.
Vous devez réaliser le graphique pour un seul des 4 parcs suivants (à votre choix) :
- Parc Jean-Marc-Gauthier
- Parc Bardy
- Parc De Beaumont
- Parc Dollard-Des Ormeaux
- L'image générée doit se nommée
figure2.png;
- L'image générée doit se nommée
figure2.png;
- L'image générée doit se nommée
figure2.png;
- L'image générée doit se nommée
figure2.png;
ASTUCES
- Pour la lisibilité des étiquettes de l'axe des x :
- Faite pivoter le texte de 45;
- Mettez un alignement horizontale à droite;
- Regroupez vos données et générez des statistiques avant la visualisation;
- Pour créer un diagramme à barres, vous pouvez utiliser
df.plot(kind="bar").
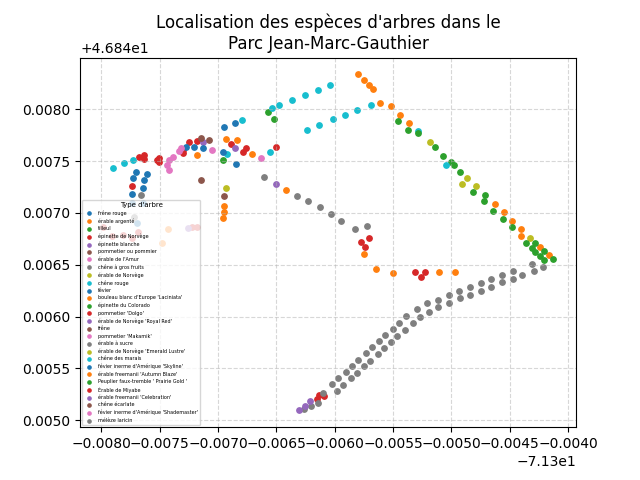
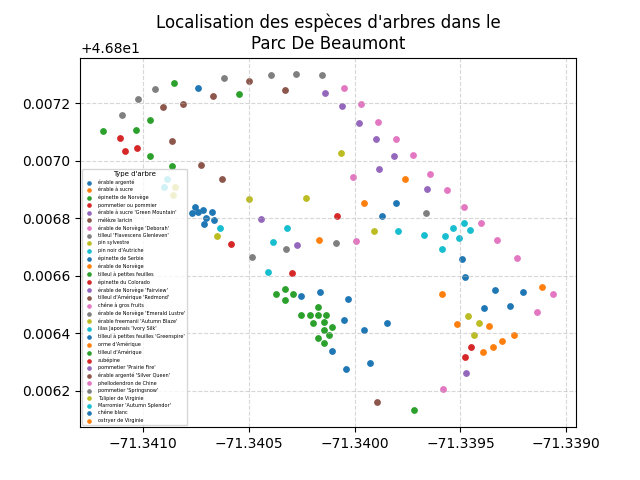
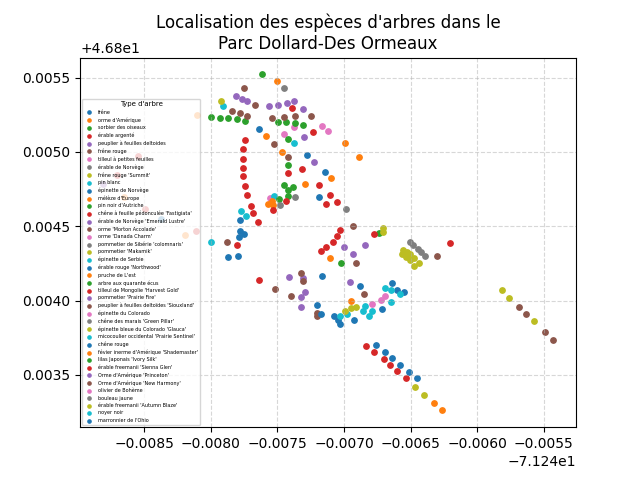
Un graphique montrant la localisation de tous les arbres d'un parc.
Vous devez réaliser le graphique pour un seul des 4 parcs suivants (à votre choix) :
- Parc Jean-Marc-Gauthier
- Parc Bardy
- Parc De Beaumont
- Parc Dollard-Des Ormeaux
- L'image générée doit se nommée
figure3.png;

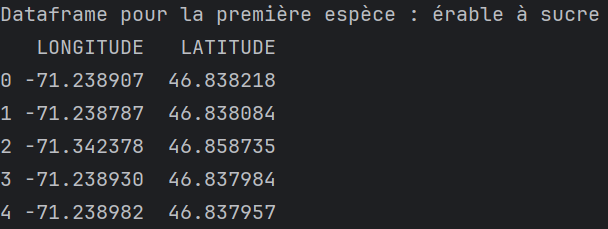
- L'image générée doit se nommée
figure3.png;
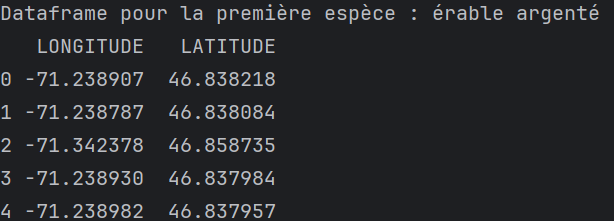
- L'image générée doit se nommée
figure3.png;
- L'image générée doit se nommée
figure3.png;
ASTUCES
- Récupérez une liste des espèces pour la région spécifiée;
- Pour chacune des espèces de la liste :
- Récupérez les données pour cette espèce (dans la région);
- Ajoutez-les au graphique à l'aide d'un nuage de points avec une taille de marqueur de
15;
- La légende doit avoir :
- le titre Type d'arbre avec une taille de
7; - son positionnement en bas à gauche;
- les étiquettes de la légende doivent avoir une taille de
3.5; - la mise à l'échelle des marqueurs des éléments doit être de
0.6.
- le titre Type d'arbre avec une taille de
Un graphique montrant la taille des diamètres d'une espèce d'arbre de votre choix.
Vous devez réaliser le graphique pour un seul des 4 parcs suivants (à votre choix) :
- érable de Norvège
- bouleau à papier
- chêne rouge
- épinette du Colorado
- L'image générée doit se nommée
figure4.png;
- L'image générée doit se nommée
figure4.png;
- L'image générée doit se nommée
figure4.png;
- L'image générée doit se nommée
figure4.png;
ASTUCES
Pour réaliser cette figure, suivez les étapes suivantes :
Étape #1 - Préparation de la liste des topographies (1er DataFrame)
- Filtrer les données pour ne conserver que l'espèce visée et les entrées dont le nom de la topographie contient le terme « Parc »;
- Grouper les données par topographie, puis calculer le nombre d'éléments par groupe;
- Trier les résultats par ordre décroissant et ne conserver que les 10 premiers;
- Extraire les noms des groupes (les topographies) sous forme de liste à l'aide de l'instruction : mon_dataframe.index.tolist().
Étape #2 - Filtrage des données sources (2e DataFrame)
- Filtrer les données de ce second DataFrame pour obtenir uniquement les entrées
de l'espèce désirée dont la topographie fait partie de la liste des 10 précédemment identifiées.
Étape #3 - Visualisation
- Générer la boîte à moustaches (boxplot) à partir du résultat obtenu avec le deuxième DataFrame.
Le script autocorrection.py se limite à la correction des 6 questions d'analyse.
Il détecte automatiquement votre progression et exécute des tests en conséquence.
⚠️ Pour que le script fonctionne correctement, il faut absolument que les fonctions possèdent dans leurs docstrings les abréviations demandées.
Le script nécessite au préalable l'installation du package requests (voir la procédure d'installation d'un package).
Cette bibliothèque permet de télécharger des fichiers en ligne par programmation ; elle est utilisée ici pour vérifier si une nouvelle version du script est disponible et pour la télécharger automatiquement.
Limitations du script
Le script possède certaines limites et ne vérifie pas les points suivants (qui peuvent vous faire perdre des points) :
- La cohérence de vos docstrings ainsi que la qualité du français;
- La présence de code inutile ou redondant à l'intérieur de vos fonctions;
- Le respect de la consigne exigeant au moins cinq commits dans votre dépôt GitHub;
- Les autres éléments à réaliser, comme la création du fichier sommaire.txt et la conformité des figures à produire.
Le projet fonctionne sans plantage et correctement, et le code est clair et facile à lire. Ce pointage fonctionne en négatif. Si le projet fonctionne correctement en tout temps, vous conservez votre note. Dans le cas contraire, vous perdez des points avec un maximum de 2.
- Plantage (un script qui plante lorsqu'on l'exécute) -1 point
- Code illisible (ex : noms de variables incompréhensibles, difficulté à comprendre le code) -1 point
- Information affichée incohérente -1 point
- Autre cas...