🐼 Pandas
- Intro
- Explorer
- Filtrer / Trier
- Sélectionner
- Parcourir
- Nettoyer
- Transformer
- Statistiques
- Exporter
- Visualiser
- Activités
À la rencontre 10, nous avons appris à utiliser NumPy faire des calculs sur des tableaux de nombres. NumPy est puissant, mais il a une limite : il travaille sur des données d’un seul type (tous des nombres, ou tous des textes). Dans la réalité, un jeu de données scientifiques contient souvent des colonnes de types différents : des mesures numériques, des dates, des catégories, des noms. Pour manipuler ce genre de données, NumPy seul devient vite insuffisant :
import numpy as np
# Avec NumPy : difficile de mélanger des types
patient_ids = np.array(["P001", "P002", "P003", "P004"])
ages = np.array([34, 58, 45, 27])
glycemies = np.array([5.2, 7.8, 6.1, 4.9])
diagnostics = np.array(["normal", "diabete", "pre_diabete", "normal"])
# Pour filtrer les patients avec une glycémie élevée, il faut jongler entre 4 tableaux séparés...
masque = glycemies > 6.0
print(patient_ids[masque]) # ["P002" "P003"]
print(diagnostics[masque]) # ["diabete" "pre_diabete"]
C’est là qu’intervient 🐼 Pandas : il regroupe toutes ces colonnes dans un seul objet, le DataFrame, et offre des outils pour les manipuler facilement.
Pour le TP2, vous devrez manipuler des données réelles. Voici les étapes typiques d’un pipeline d’analyse, et les onglets qui y correspondent :
| Étape | Ce qu’on fait | Onglet |
|---|---|---|
| 📥 Charger | Importer un fichier CSV dans un DataFrame | Explorer |
| 🔍 Filtrer | Filtrer et trier les données | Filtrer / Trier |
| 🎯 Sélectionner | Choisir des colonnes ou des lignes | Sélectionner |
| 🔁 Parcourir | Itérer sur les lignes ou colonnes | Parcourir |
| 🧹 Nettoyer | Gérer les valeurs manquantes et les doublons | Nettoyer |
| 🧮 Transformer | Créer de nouvelles colonnes | Transformer |
| 📊 Analyser | Calculer des statistiques, regrouper | Statistiques |
| 📤 Exporter | Enregistrer un DataFrame dans un fichier CSV | Exporter |
| 📈 Visualiser | Tracer des graphiques | Visualiser |
Pandas n’est qu’une des bibliothèques utilisées en science des données.
Pour votre culture générale, voici l’écosystème Python dans ce domaine :
- 🐼 Pandas : manipulation de données tabulaires (c’est le sujet de cette rencontre)
- 🎨 Matplotlib : visualisation de données (on la connait déjà)
- 🔢 NumPy : calcul scientifique sur des tableaux (vue à la rencontre 10)
- 🤖 Scikit-learn : apprentissage automatique (prochain cours)
- 🧠 Keras / TensorFlow : apprentissage profond (deep learning) (cours ultérieurs)
Les explications de cette section étaient-elles claires ?
On connait déjà les dictionnaires et les listes en Python. Un DataFrame Pandas, c'est exactement ça : un dictionnaire dont les valeurs sont des listes de même longueur.
import pandas as pd
data = {
"patient_id": ["P001", "P002", "P003", "P004" ],
"age": [34, 58, 45, 27 ],
"glycemie_mmol_L": [5.2, 7.8, 6.1, 4.9 ],
"tension_systolique": [118, 142, 135, 112 ],
"diagnostic": ["normal", "diabete", "pre_diabete", "normal"],
}
df = pd.DataFrame(data)
print(df)
patient_id age glycemie_mmol_L tension_systolique diagnostic
0 P001 34 5.2 118 normal
1 P002 58 7.8 142 diabete
2 P003 45 6.1 135 pre_diabete
3 P004 27 4.9 112 normal
Quelques points importants à observer :
- Les clés du dictionnaire deviennent les noms des colonnes.
- Chaque liste devient une colonne de données.
- La colonne
0, 1, 2, 3à gauche est l'index (numéro de ligne automatique). - Chaque ligne est un enregistrement (ici, un patient).
dfest juste le nom de la variable qui stocke le DataFrame : on aurait pu l'appelerpatientsouplantesou n'importe quoi d'autre.
Un DataFrame peut avoir des milliers de lignes : c'est là que Pandas devient indispensable, là où manipuler des listes et des dictionnaires à la main devient ingérable.
Sous le capot, chaque colonne d'un DataFrame est stockée comme un tableau NumPy (ndarray). C'est pour ça que Pandas hérite de la même rapidité de calcul que NumPy, et que des opérations comme df["col"] * 2 fonctionnent sans boucle, exactement comme tableau * 2 en NumPy.
Dans l'exemple précédent, les données étaient écrites directement dans le code. En pratique, les données proviennent presque toujours de fichiers externes : bases de données, exports Excel, JSON… Le format le plus courant est le CSV (Comma-Separated Values) : un simple fichier texte où chaque ligne est un enregistrement et chaque valeur est séparée par un délimiteur (souvent une virgule).
Pandas permet de charger un fichier CSV en une seule ligne avec pd.read_csv(), qui retourne directement un DataFrame prêt à être exploré.
Le fichier tips_dataset.csv regroupe des données collectées dans un restaurant : pour chaque repas, on y retrouve le montant de la facture, le pourboire laissé, le jour, le moment de la journée, la taille du groupe, et quelques informations sur le serveur.
Téléchargez-le, placez-le à la racine d'un projet PyCharm, puis chargez-le :
import pandas as pd
df = pd.read_csv('tips_dataset.csv') # → retourne un DataFrame
Ces données serviront à illustrer toutes les opérations qui suivent! 🎯
df.head() retourne les 5 premières lignes par défaut. On peut passer un nombre en argument pour en voir plus.
print(df.head()) # → les 5 premières lignes
print(df.head(20)) # → les 20 premières lignes
Résultat :
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Si un DataFrame a trop de colonnes ou du contenu trop long, certaines colonnes peuvent être remplacées par des ....
Dans ce cas, on peut ajouter ces 2 instructions juste après les importations en haut du script :
import pandas as pd
pd.set_option('display.max_colwidth', None)
pd.set_option('display.expand_frame_repr', False)
df.shape retourne un tuple (nombre de lignes, nombre de colonnes).
C'est la façon la plus rapide de connaître la taille d'un DataFrame.
print(df.shape) # → (244, 7)
print(df.shape[0]) # → 244 (nombre de lignes)
print(df.shape[1]) # → 7 (nombre de colonnes)
len(df) est une alternative à df.shape[0] pour obtenir uniquement le nombre de lignes.
print(len(df)) # → 244
print(df.shape[0]) # → 244 (même résultat)
df.columns retourne les noms des colonnes. On appelle .tolist() pour obtenir une liste Python ordinaire.
print(df.columns.tolist()) # → ['total_bill', 'tip', 'sex', 'smoker', 'day', 'time', 'size']
Dans un DataFrame, chaque colonne a un type de données (Dtype). On a déjà rencontré ce concept en NumPy avec tableau.dtype : c'est exactement la même notion, appliquée à une colonne. Voici les types les plus courants et leur équivalent Python :
| Dtype Pandas | Équivalent Python | Description |
|---|---|---|
| int64 | int | Nombre entier |
| float64 | float | Nombre décimal |
| object | str | Texte (chaîne de caractères) |
| bool | bool | Valeur booléenne (True / False) |
df.info() affiche le nombre de lignes, le nom et le Dtype de chaque colonne, et le nombre de valeurs non-nulles.
C'est souvent la première chose à appeler pour détecter des colonnes mal typées ou des valeurs manquantes.
df.info() # affiche directement — pas besoin de print()
Résultat :
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null object
3 smoker 244 non-null object
4 day 244 non-null object
5 time 244 non-null object
6 size 244 non-null int64
dtypes: float64(2), int64(1), object(3)
memory usage: 13.5+ KB
- RangeIndex: 244 entries — 244 lignes, indexées de 0 à 243
- float64 — nombre décimal, aucune valeur manquante (244 non-null)
- object — texte (str en Python)
- int64 — nombre entier
- dtypes: float64(2), int64(1), object(3) — résumé des types présents dans le DataFrame
df.describe() retourne un résumé statistique rapide pour toutes les colonnes numériques.
print(df.describe())
Résultat :
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000
- count — nombre de valeurs non-nulles
- mean — moyenne
- std — écart-type (mesure la dispersion des valeurs)
- min / max — valeur minimale et maximale
- 25% / 50% / 75% — quartiles (50% = médiane)
Avant d'écrire du code, on peut explorer un fichier CSV directement dans PyCharm en faisant un double-clic dessus. Deux modes sont disponibles en bas de l'éditeur : Mode Text (contenu brut) et Mode Data (tableau interactif avec filtre, tri et recherche).
Mode Text - affichage brut du fichier
Mode Data - affichage tabulaire interactif
⚠️ PyCharm (comme Excel, limité à ~1 million de lignes) n'affiche pas nécessairement toutes les lignes pour des raisons de performance. C'est précisément pourquoi Pandas est indispensable : il peut traiter des fichiers de plusieurs millions de lignes sans limitation.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Charger un CSV | df = pd.read_csv('fichier.csv') | Retourne un DataFrame |
| Aperçu des données | df_apercu = df.head(5) | Retourne les 5 premières lignes |
| Dimensions | dimensions = df.shape | Retourne (244, 7) : lignes, colonnes |
| Nombre de lignes | n = len(df) | Retourne le nombre de lignes |
| Noms des colonnes | colonnes = df.columns.tolist() | Retourne une liste des noms de colonnes |
| Types et valeurs manquantes | df.info() | Affiche directement dans la console |
| Statistiques descriptives | df_stats = df.describe() | Retourne un DataFrame (colonnes numériques) |
Les explications de cette section étaient-elles claires ?
Filtrer un DataFrame, c'est ne garder que les lignes qui satisfont une condition, comme un tamis qui laisse passer certaines données et en retient d'autres.
Par exemple, sur un DataFrame de 244 repas dans un restaurant, on pourrait vouloir garder seulement :
- les repas où le pourboire laissé dépasse 5 $
- les repas du dimanche soir
- les repas avec un groupe de plus de 4 personnes
Le résultat est toujours un nouveau DataFrame. Le DataFrame original df n'est pas modifié, et c'est pourquoi on va généralement stocker le résultat dans une nouvelle variable :
df_gros_pourboires = df[df["tip"] > 5]
Quand on écrit df[df["tip"] > 5], Pandas effectue deux étapes :
df["tip"] > 5produit une série de booléens :Truepour chaque ligne où le pourboire dépasse 5,Falsesinondf[...]ne conserve que les lignes où la valeur estTrue
C'est exactement la même logique que les masques booléens vus à la rencontre 10 : t[t > 5] en NumPy et df[df["tip"] > 5] en Pandas utilisent le même mécanisme. La seule différence : NumPy filtre des valeurs dans un tableau, Pandas filtre des lignes dans un DataFrame.
Par exemple, on pourrait très bien d'abord créer le masque booléen, puis ensuite l'appliquer :
masque = df["tip"] > 5
df_gros_pourboires = df[masque]
Mais en général, on combine les deux étapes en une seule ligne pour plus de concision :
df_gros_pourboires = df[df["tip"] > 5]
print(df_gros_pourboires)
Résultat :
total_bill tip sex smoker day time size
23 39.42 7.58 Male No Sat Dinner 4
44 30.40 5.60 Male No Sun Dinner 4
47 32.40 6.00 Male No Sun Dinner 4
52 34.81 5.20 Female No Sun Dinner 4
59 48.27 6.73 Male No Sat Dinner 4
...
Un filtre simple compare les valeurs d'une colonne à une valeur de référence. On peut utiliser les opérateurs de comparaison habituels.
# Comparaison numérique
df_gros_pourboires = df[df["tip"] > 5] # pourboire supérieur à 5 $
df_petites_tables = df[df["size"] <= 2] # tables de 1 ou 2 personnes
df_facture_exacte = df[df["total_bill"] == 16.99] # montant exact
# Comparaison sur du texte (égalité exacte)
df_souper = df[df["time"] == "Dinner"] # repas du soir seulement
df_non_fumeurs = df[df["smoker"] == "No"] # tables non-fumeurs
df_samedi = df[df["day"] == "Sat"] # repas du samedi
Pour filtrer sur le contenu d'une colonne textuelle, Pandas offre des méthodes .str..
Elles sont utiles quand on veut chercher une sous-chaîne plutôt que vérifier une égalité exacte.
df_jours_th = df[df["day"].str.contains("Th")] # "Thur" contient "Th"
df_jours_longs = df[df["day"].str.len() > 3] # "Thur" a 4 caractères, "Fri" en a 3
df_majuscule_f = df[df["sex"].str.startswith("F")] # "Female" commence par "F"
On peut combiner plusieurs conditions avec & (ET) et | (OU). Chaque condition doit être entre parenthèses (comme avec NumPy).
# & : les deux conditions doivent être vraies
df_dimanche_souper = df[(df["day"] == "Sun") & (df["time"] == "Dinner")]
df_fumeurs_genereux = df[(df["smoker"] == "Yes") & (df["tip"] > 4)]
# | : au moins une des conditions doit être vraie
df_extremes_facture = df[(df["total_bill"] < 5) | (df["total_bill"] > 45)]
df_repas_courts = df[(df["time"] == "Lunch") | (df["size"] == 1)]
Sans parenthèses autour de chaque condition, Python interprète mal l'expression et génère une erreur. Écris toujours (cond1) & (cond2), jamais cond1 & cond2. C'est la même règle que pour les masques booléens en NumPy : les parenthèses sont nécessaires lorsque plusieurs conditions sont combinées.
Quand on veut filtrer sur plusieurs valeurs d'une même colonne, isin() est plus lisible qu'une suite de |.
# Garder seulement les repas du jeudi et du vendredi
df_jours_semaine = df[df["day"].isin(["Thur", "Fri"])]
# Garder seulement les grandes tables (4, 5 ou 6 personnes)
df_grandes_tables = df[df["size"].isin([4, 5, 6])]
isin() vs |df[df["day"].isin(["Thur", "Fri"])] est équivalent à df[(df["day"] == "Thur") | (df["day"] == "Fri")], mais beaucoup plus lisible quand la liste grandit.
Trier un DataFrame, c'est réordonner ses lignes selon les valeurs d'une ou plusieurs colonnes.
Par défaut, Pandas trie en ordre croissant (du plus petit au plus grand, ou de A à Z). On peut inverser cet ordre avec ascending=False.
sort_values() retourne un nouveau DataFrame trié. Le DataFrame original n'est pas modifié.
df_trie1 = df.sort_values(by="total_bill") # → ordre croissant par défaut
df_trie2 = df.sort_values(by="tip", ascending=False) # → ordre décroissant
df_trie3 = df.sort_values(by=["day", "total_bill"]) # → tri sur 2 colonnes
On peut chaîner un filtre et un tri en une seule instruction. Les deux versions ci-dessous produisent exactement le même résultat :
# Version détaillée : plus facile à lire et à déboguer
df_version1 = df[df["day"].isin(["Sun", "Sat"])]
df_version1 = df_version1.sort_values(by="total_bill")
# Version compacte ("Method Chaining") : une seule ligne
df_version2 = df[df["day"].isin(["Sun", "Sat"])].sort_values(by="total_bill")
Les deux contiennent les repas de fin de semaine, triés par montant de facture.
Plus tôt on réduit la taille du jeu de données, plus les opérations suivantes sont rapides. Commencez toujours par filtrer avant de trier.
Quand on combine plusieurs opérations, il peut être difficile d'identifier la source d'une erreur. Le débogage est souvent plus simple en décomposant les instructions sur des lignes distinctes : cela permet de vérifier l'état du DataFrame après chaque transformation.
En mode débogage, PyCharm offre une fonctionnalité très pratique : le lien "View as DataFrame", visible dans le panneau des variables. Il permet d'inspecter visuellement le contenu d'un DataFrame sous forme de tableau interactif, directement depuis le débogueur.
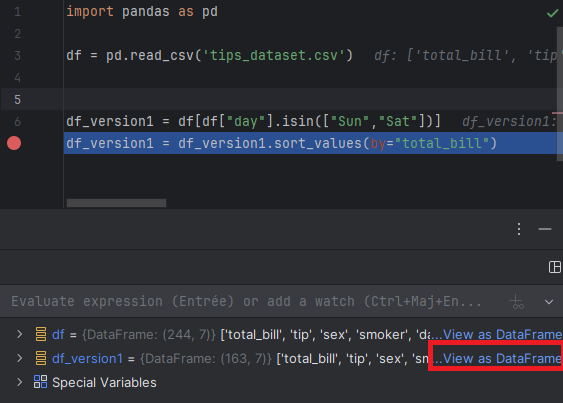
👆 Cliquez sur "View as DataFrame" dans le panneau des variables pour inspecter un DataFrame en cours d'exécution.
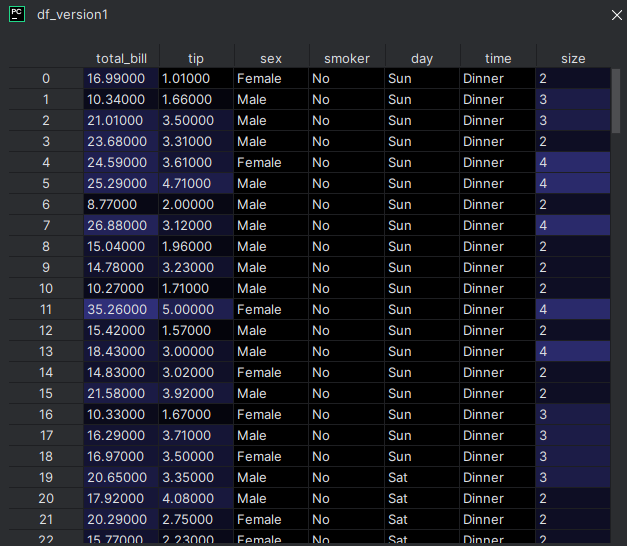
📊 Le contenu du DataFrame s'affiche dans une vue tabulaire claire, avec toutes ses lignes et colonnes.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Filtre simple (nombre) | df_filtrer = df[df["tip"] > 5] | Pourboire supérieur à 5 $ |
| Filtre simple (texte) | df_filtrer = df[df["time"] == "Dinner"] | Égalité exacte sur une colonne texte |
| Filtre texte (.str.) | df_filtrer = df[df["day"].str.contains("Th")] | Colonne contient une sous-chaîne |
| Filtre ET | df_filtrer = df[(df["day"] == "Sun") & (df["time"] == "Dinner")] | Les deux conditions vraies |
| Filtre OU | df_filtrer = df[(df["size"] == 1) | (df["size"] == 2)] | Au moins une condition vraie |
| Filtre liste | df_filtrer = df[df["day"].isin(["Thur", "Fri"])] | Valeur parmi une liste |
| Trier croissant | df_trier = df.sort_values(by="tip") | Du plus petit au plus grand |
| Trier décroissant | df_trier = df.sort_values(by="tip", ascending=False) | Du plus grand au plus petit |
| Trier multi-colonnes | df_trier = df.sort_values(by=["day", "tip"]) | Tri sur plusieurs colonnes |
| Chaîner filtre + tri | df_resultat = df[df["day"] == "Sun"].sort_values(by="tip") | Filtrer puis trier en une ligne |
Les explications de cette section étaient-elles claires ?
Sélectionner, c’est extraire une partie d’un DataFrame : certaines colonnes, certaines lignes, ou une cellule précise. C’est différent de filtrer : filtrer choisit des lignes selon une condition, sélectionner choisit quelles colonnes ou positions on veut voir.
Selon ce qu’on sélectionne, Pandas retourne l’un de ces trois types :
- DataFrame : un tableau à deux dimensions, comme
dflui-même - Series : une seule colonne ou une seule ligne, c’est-à-dire une liste de valeurs avec un index
- valeur scalaire : une seule valeur, comme un
intou unfloat
Le type retourné dépend aussi des crochets utilisés :
| Ce qu’on sélectionne | Syntaxe | Type retourné |
|---|---|---|
| Plusieurs colonnes | df[["col1", "col2"]] | DataFrame |
| Une seule colonne | df["col"] | Series |
| Une seule colonne (format tableau) | df[["col"]] | DataFrame |
| Plusieurs lignes (par position) | df.iloc[2:5] | DataFrame |
| Une seule ligne (par position) | df.iloc[3] | Series |
| Une cellule (par position) | df.iat[3, 0] | valeur scalaire (float, string, etc.) |
| Une cellule (par étiquette) | df.at[3, "tip"] | valeur scalaire (float, string, etc.) |
Lorsqu'on sélectionne une seule colonne d'un DataFrame, le résultat est une Series.
Lorsqu'on sélectionne une seule ligne, le résultat est aussi une Series.
Une Series ressemble à un dictionnaire parce qu’elle associe une étiquette d’index à chaque valeur :
- Dans une colonne, l’index correspond aux lignes du DataFrame.
- Dans une ligne, l’index correspond aux colonnes du DataFrame.
Mais une Series ressemble aussi à un tableau NumPy, parce qu’on peut faire des opérations sur toutes ses valeurs d’un coup :
df["tip"] * 2
On peut donc voir une Series comme une colonne ou une ligne de données avec un index.
C’est un objet propre à Pandas, qui combine certaines idées du dictionnaire et du tableau numérique.
Pour extraire une ou plusieurs colonnes d'un DataFrame, on utilise les crochets []. Le type retourné dépend du nombre de crochets utilisés.
Plusieurs colonnes → DataFrame (doubles crochets)
df_apercu = df[["total_bill", "tip", "day"]] # on donne une liste de colonnes → ["total_bill", "tip", "day"]
print(df_apercu.head(3))
Résultat :
total_bill tip day
0 16.99 1.01 Sun
1 10.34 1.66 Sun
2 21.01 3.50 Sun
Une seule colonne → Series (crochets simples)
serie_tip = df["tip"] # on donne un seul nom de colonne (pas une liste) → "tip"
print(serie_tip.head(3))
Résultat :
0 1.01
1 1.66
2 3.50
Name: tip, dtype: float64
Une seule colonne → DataFrame (doubles crochets)
df_tip = df[["tip"]] # on donne une liste qui contient un seul nom de colonne → ["tip"]
print(df_tip.head(3))
Résultat :
tip
0 1.01
1 1.66
2 3.50
df["tip"] retourne une Series (une dimension).
df[["tip"]] retourne un DataFrame (deux dimensions).
En cas de doute, utilise print(type(...)) pour vérifier.
print(type(df["tip"])) # <class ‘pandas.core.series.Series’>
print(type(df[["tip"]])) # <class ‘pandas.core.frame.DataFrame’>
iloc sélectionne des lignes par position numérique, exactement comme le slicing de liste.
# Plusieurs lignes → DataFrame
df_debut = df.iloc[0:3]
print(df_debut)
Résultat :
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
On peut aussi sélectionner des lignes spécifiques par leur position :
df.iloc[[0, 5, 10]] # → DataFrame — lignes 0, 5 et 10 précisément - liste de lignes → [0, 5, 10]
df.iloc[[3]] # → DataFrame — une seule ligne (doubles crochets) - liste d'une ligne → [3]
df.iloc[3] # → Series — une seule ligne (crochets simples) - ligne seule → 3
Pour accéder à une seule valeur, df.iat[] (par position) et df.at[] (par étiquette) sont les méthodes recommandées.
# Par position : df.iat[numéro_ligne, numéro_colonne]
valeur = df.iat[0, 1] # ligne 0, colonne 1 → tip = 1.01
# Par étiquette : df.at[index, nom_colonne]
valeur = df.at[0, "tip"] # ligne d’index 0, colonne "tip" → 1.01
loc sélectionne par étiquette de ligne. Dans un DataFrame normal les étiquettes sont numériques (0, 1, 2, ...), donc loc et iloc donnent le même résultat. loc devient indispensable quand les lignes ont des étiquettes textuelles, comme avec df.describe() :
desc = df.describe()
print(desc)
Résultat :
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000
Les lignes portent des étiquettes textuelles (mean, min, max...). On utilise loc pour extraire une valeur précise :
# Extraire la moyenne de "tip"
mean_tip = desc.loc["mean", "tip"] # → 2.998279
# Extraire le maximum de "total_bill"
max_bill = desc.loc["max", "total_bill"] # → 50.81
Syntaxe : df.loc[étiquette_ligne, nom_colonne]
.values : récupérer le tableau NumPy sous-jacentSous le capot, chaque colonne Pandas est stockée comme un tableau NumPy. On peut y accéder directement avec .values, ce qui retourne un ndarray prêt à être utilisé avec toutes les fonctions NumPy que l'on connait :
import numpy as np
tips = df["tip"].values
print(type(tips)) # <class 'numpy.ndarray'>
print(np.clip(tips, 0, 5)) # plafonner les pourboires à 5 $
C'est utile quand on veut appliquer des opérations NumPy (np.clip, np.where, np.mean, etc.) sur des données provenant d'un DataFrame.
| Opération | Syntaxe | Type retourné |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Plusieurs colonnes | df_selection = df[["total_bill", "tip"]] | DataFrame |
| Une colonne (Series) | serie = df["tip"] | Series |
| Une colonne (DataFrame) | df_selection = df[["tip"]] | DataFrame |
| Lignes par position | df_selection = df.iloc[3:10] | DataFrame |
| Ligne précise (Series) | ligne = df.iloc[3] | Series |
| Ligne précise (DataFrame) | df_selection = df.iloc[[3]] | DataFrame |
| Cellule par position | valeur = df.iat[3, 0] | valeur scalaire |
| Cellule par étiquette | valeur = df.at[3, "tip"] | valeur scalaire |
| Cellule avec loc | valeur = df.loc["mean", "tip"] | valeur scalaire |
| Colonne en tableau NumPy | tableau = df["tip"].values | ndarray NumPy |
Les explications de cette section étaient-elles claires ?
Parcourir un DataFrame, c’est passer sur chaque ligne ou chaque valeur une par une pour effectuer une opération personnalisée. C’est utile quand on veut faire un traitement pour chaque élément, appliquer une logique conditionnelle complexe, ou encore construire une nouvelle liste à partir des données.
Si on n’a besoin que d’une partie des données, on filtre et on trie le DataFrame avant de le parcourir. Parcourir moins de lignes, c’est un code plus rapide et plus lisible.
Les exemples qui suivent utilisent le DataFrame df_consoles, qui regroupe des données sur les consoles de jeux vidéo les plus vendues. Chaque ligne représente une console, avec son année de sortie, ses ventes estimées (en millions d’unités) et son jeu le plus vendu.
import pandas as pd
df_consoles = pd.DataFrame({
"Console": ["PlayStation 5", "Xbox Series X", "Nintendo Switch 2"],
"Année_Sortie": [2020, 2020, 2025],
"Unités_Vendues_Millions": [92.0, 35.0, 19.6],
})
iterrows() permet de parcourir les lignes d’un DataFrame avec une boucle for. À chaque itération, on reçoit l’index de la ligne et son contenu sous forme de Series.
Cette Series a pour index les noms des colonnes du DataFrame. On peut donc accéder à une valeur par nom, exactement comme dans un dictionnaire.
Exemple simple avec une seule colonne :
for index, row in df_consoles.iterrows():
print(row["Console"])
l'instruction row["Console"] retourne la valeur de la colonne Console pour la ligne courante.
Résultat :
PlayStation 5
Xbox Series X
Nintendo Switch 2
Exemple avec plusieurs colonnes :
for index, row in df_consoles.iterrows():
print(f"{row["Console"]} ({row["Année_Sortie"]}) : {row["Unités_Vendues_Millions"]}M unités vendues")
Résultat :
PlayStation 5 (2020) : 92.0M unités vendues
Xbox Series X (2020) : 35.0M unités vendues
Nintendo Switch 2 (2025) : 19.6M unités vendues
index et row sont des conventionsOn peut les remplacer par n’importe quel nom de variable. for i, ligne in df.iterrows() fonctionne exactement pareil.
iterrows() est lent sur de grands jeux de donnéesPour limiter l'impact, on filtre le DataFrame avant de le parcourir : moins de lignes à traiter, c'est un code plus rapide.
Si le but est de créer de nouvelles colonnes ou modifier des colonnes existantes, iterrows() n'est pas la bonne approche.
Les transformations vectorielles de Pandas sont nettement plus performantes et sont vues dans l'onglet Transformer.
Pour parcourir les valeurs d’une seule colonne (une Series), on itère directement sur la colonne comme sur une liste :
for console in df_consoles["Console"]:
print(console)
Résultat :
PlayStation 5
Xbox Series X
Nintendo Switch 2
Une Series Pandas n’est pas une liste Python ordinaire. Certaines fonctions Python n’acceptent que des listes, pas des Series. Pour convertir, on utilise .tolist() :
liste_consoles = df_consoles["Console"].tolist()
print(liste_consoles) # → [‘PlayStation 5’, ‘Xbox Series X’, ‘Nintendo Switch 2’]
Certaines fonctions Python s’attendent à recevoir une liste et produisent une erreur si on leur passe une Series. .tolist() règle ce problème.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Parcourir ligne par ligne | for index, row in df.iterrows(): | index = numéro de ligne, row = Series |
| Accéder à une valeur | row["Console"] | Valeur de la colonne "Console" pour la ligne courante |
| Parcourir une colonne | for val in df["Console"]: | Itère sur les valeurs d'une Series |
| Convertir en liste | df["Console"].tolist() | Retourne une liste Python ordinaire |
Les explications de cette section étaient-elles claires ?
Le principe du Garbage In, Garbage Out s'applique directement en analyse de données : si les données de base sont erronées, tous les calculs qui en découlent le seront aussi.
On nettoie pour trois raisons principales : éviter les erreurs de calcul causées par les valeurs manquantes (NaN, Not A Number), assurer la précision en éliminant les doublons ou les valeurs aberrantes, et faciliter la visualisation en évitant que des points parasites faussent l'échelle d'un graphique.
Les exemples qui suivent utilisent le DataFrame df_joueurs, qui contient des données volontairement imparfaites : valeurs manquantes et doublons inclus.
import pandas as pd
df_joueurs = pd.DataFrame({
"Pseudo": ["Sakura99", "DarkLink", "Sakura99", "NovaStar", "GhostX"],
"Score": [4200, None, 4200, 3100, None],
"Niveau": ["12", None, "12", None, "5"],
"Région": ["QC", "ON", "QC", None, "BC"]
})
Résultat :
Pseudo Score Niveau Région
0 Sakura99 4200.0 12 QC
1 DarkLink NaN NaN ON
2 Sakura99 4200.0 12 QC
3 NovaStar 3100.0 NaN NaN
4 GhostX NaN 5 BC
On remarque déjà que la ligne 2 est un doublon exact de la ligne 0, que Score et Niveau ont des NaN, et que Région est manquante pour NovaStar.
On peut aussi vérifier le type de chaque colonne avec .dtypes :
print(df_joueurs.dtypes)
Résultat :
Pseudo object
Score float64
Niveau object
Région object
dtype: object
La colonne Niveau est de type object, car les valeurs ont été écrites entre guillemets ("12", "5") dans les données de départ.
Pour Pandas, ce ne sont donc pas encore des nombres, mais du texte. On corrigera ce probl�ème plus loin.
Avant de nettoyer, il est utile de savoir quelles colonnes contiennent des NaN et combien. .isnull().sum() retourne le nombre de valeurs manquantes par colonne :
print(df_joueurs.isnull().sum())
Résultat :
Pseudo 0
Score 2
Niveau 2
Région 1
dtype: int64
On voit immédiatement que Score et Niveau ont chacun 2 valeurs manquantes, et que Région en a 1. Pseudo est complet. C'est ce qui guide le choix de nettoyage : quelles colonnes cibler et quelle approche utiliser.
dropna() retourne un nouveau DataFrame sans modifier l'original.
Supprimer toutes les lignes qui contiennent au moins un NaN :
df_propre = df_joueurs.dropna()
print(df_propre)
Résultat :
Pseudo Score Niveau Région
0 Sakura99 4200.0 12 QC
2 Sakura99 4200.0 12 QC
Seules les lignes sans aucun NaN sont conservées. C'est une approche radicale : on perd beaucoup de données.
Supprimer une ligne uniquement si une colonne critique est manquante :
df_propre = df_joueurs.dropna(subset=["Score"])
print(df_propre)
Résultat :
Pseudo Score Niveau Région
0 Sakura99 4200.0 12 QC
2 Sakura99 4200.0 12 QC
3 NovaStar 3100.0 NaN NaN
Cette forme est plus prudente : on ne supprime que les lignes où Score est vide, et on conserve les autres même si elles ont d'autres NaN.
dropna() ne modifie pas df_joueurs. Il faut assigner le résultat à une nouvelle variable (ou à df_joueurs pour écraser l'original).
Le réflexe naturel est d'appeler dropna() sans argument pour tout nettoyer d'un coup.
Le problème : on perd souvent des lignes à cause de NaN dans des colonnes qu'on n'utilise même pas.
On identifie d'abord les colonnes nécessaires à la requête.
Par exemple, si l'objectif est d'afficher les 3 joueurs avec les meilleurs scores de la région QC :
df_joueurs[df_joueurs["Région"] == "QC"][["Pseudo", "Score"]].sort_values("Score", ascending=False).head(3)
Cette requête utilise Région (filtrer), Score (trier) et Pseudo (afficher). La colonne Niveau n'intervient pas.
df_propre = df_joueurs.dropna() # ❌ perd aussi les lignes où Niveau est NaN
df_propre = df_joueurs.dropna(subset=["Région", "Score"]) # ✅ cible uniquement les colonnes importantes
drop_duplicates() élimine les lignes qui sont des copies exactes d'autres lignes. C'est fréquent lors de la fusion de plusieurs fichiers.
df_propre = df_joueurs.drop_duplicates()
print(df_propre)
Résultat :
Pseudo Score Niveau Région
0 Sakura99 4200.0 12 QC
1 DarkLink NaN NaN ON
3 NovaStar 3100.0 NaN NaN
4 GhostX NaN 5 BC
La ligne 2 (doublon exact de Sakura99) a été supprimée. Pandas conserve la première occurrence et retire les suivantes.
Comme dropna(), drop_duplicates() ne modifie pas df_joueurs. Il faut assigner le résultat à une nouvelle variable (ou à df_joueurs pour écraser l'original).
Au lieu de supprimer une ligne, on peut parfois remplacer un NaN par une valeur de remplacement.
⚠️ Il ne faut toutefois pas remplacer les valeurs manquantes automatiquement. Le choix de la valeur dépend du contexte, de la colonne et de la question qu’on veut analyser.
Quelques stratégies possibles :
| Situation | Exemple de remplacement possible |
|---|---|
| Catégorie inconnue | "Inconnue" |
| Valeur numérique manquante | moyenne, médiane ou valeur fixe |
| Valeur absente qui signifie réellement zéro | 0 |
| Colonne peu importante pour l’analyse | ne pas remplacer, ou ignorer la colonne |
Les exemples ci-dessous montrent différentes possibilités. Ils ne veulent pas dire qu’il faut toujours remplacer les valeurs manquantes par la moyenne ou par la médiane.
Contrairement à dropna() et drop_duplicates(), fillna() est ici utilisé pour modifier le contenu d'une colonne directement : on applique une transformation sur la colonne et on réassigne le résultat dans df_joueurs. C'est le même principe que les transformations vues dans l'onglet Transformer.
Exemple : remplacer par une valeur fixe (colonne texte)
df_joueurs["Région"] = df_joueurs["Région"].fillna("Inconnue")
print(df_joueurs["Région"])
Résultat :
0 QC
1 ON
2 QC
3 Inconnue
4 BC
Exemple : remplacer par la moyenne de la colonne
moyenne_score = df_joueurs["Score"].mean()
df_joueurs["Score"] = df_joueurs["Score"].fillna(moyenne_score)
print(df_joueurs["Score"])
Résultat :
0 4200.0
1 3766.666...
2 4200.0
3 3100.0
4 3766.666...
Les NaN ont été remplacés par la moyenne des scores existants :
(4200 + 4200 + 3100) / 3 ≈ 3766.
Ce n’est pas une règle générale : c’est seulement un exemple de stratégie possible. Dans une vraie analyse, il faudrait se demander si remplacer les scores inconnus par la moyenne a du sens.
On note aussi que le doublon Sakura99 (ligne 2) est inclus dans ce calcul. Si on avait d'abord supprimé les doublons, la moyenne serait différente : (4200 + 3100) / 2 = 3650.
L'ordre des opérations de nettoyage influence donc les résultats.
.mean() s'applique aux colonnes numériques seulementPour une colonne texte, on peut utiliser une valeur fixe comme "Inconnu" ou la valeur la plus fréquente (df["col"].mode()[0]).
astype()Pandas importe parfois des nombres sous forme de texte à cause d'un caractère inattendu dans le fichier CSV.
C'est le cas de la colonne Niveau dans df_joueurs : elle a été définie avec des chaînes de caractères comme "12" plutôt que des entiers.
print(df_joueurs["Niveau"].dtype) # → object (texte)
Avant de pouvoir faire des calculs sur Niveau (moyenne, comparaisons numériques, etc.), il faut d'abord gérer les NaN, puis convertir le type :
# Étape 1 : remplacer les NaN par 0 (ou une autre valeur appropriée)
df_joueurs["Niveau"] = df_joueurs["Niveau"].fillna(0)
# Étape 2 : convertir en nombre
df_joueurs["Niveau"] = df_joueurs["Niveau"].astype(int)
print(df_joueurs["Niveau"].dtype) # → int64
Si la colonne contient des valeurs comme "N/A" ou "–", astype() produira une erreur. Il faut les nettoyer avec fillna() ou replace() avant de convertir.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Détecter les NaN | df.isnull().sum() | Nombre de NaN par colonne |
| Supprimer les NaN (tout) | df_propre = df.dropna() | Retire toute ligne avec au moins un NaN |
| Supprimer les NaN (colonne) | df_propre = df.dropna(subset=["col"]) | Retire seulement si cette colonne est vide |
| Supprimer les doublons | df_propre = df.drop_duplicates() | Retire les lignes identiques |
| Remplacer les NaN (fixe) | df["col"] = df["col"].fillna("valeur") | Remplace NaN par une valeur fixe |
| Remplacer les NaN (moyenne) | df["col"] = df["col"].fillna(df["col"].mean()) | Remplace NaN par la moyenne (numérique) |
| Convertir le type | df["col"] = df["col"].astype(float) | Change le type de la colonne |
Les explications de cette section étaient-elles claires ?
Transformer un DataFrame, c'est créer ou modifier une colonne à partir des données existantes, sans toucher aux lignes.
On calcule de nouvelles valeurs, on convertit des types ou on remplace des codes par des étiquettes lisibles.
La forme est toujours la même : on assigne une expression à une colonne du DataFrame.
Si la colonne n'existe pas encore, elle est créée. Si elle existe déjà, son contenu est remplacé :
df["nouvelle_colonne"] = expression # crée une nouvelle colonne
df["colonne_existante"] = expression # modifie une colonne existante
Contrairement au filtrage et au tri (qui retournent un nouveau DataFrame), les transformations modifient df en place en réassignant directement la colonne dans le DataFrame.
En NumPy, on a appris que tableau * 2 applique l'opération à tous les éléments sans boucle. Pandas utilise exactement le même principe : df["col"] * 2 applique la multiplication à toute la colonne en une seule instruction. On n'a pas besoin de boucle for, pour la même raison qu'en NumPy.
Les exemples qui suivent utilisent le fichier tips_dataset.csv chargé dans un DataFrame df :
import pandas as pd
df = pd.read_csv("tips_dataset.csv")
On crée une nouvelle colonne en lui assignant le résultat d'un calcul sur des colonnes existantes :
df["tip_percentage"] = (df["tip"] / df["total_bill"]) * 100
Pour vérifier le résultat, on peut afficher les colonnes source et la nouvelle colonne :
print(df[["total_bill", "tip", "tip_percentage"]].head(3))
Résultat :
total_bill tip tip_percentage
0 16.99 1.01 5.944673
1 10.34 1.66 16.054159
2 21.01 3.50 16.658258
On peut vérifier mentalement : 1.01 / 16.99 × 100 ≈ 5.94 ✓. La colonne tip_percentage est maintenant disponible dans df comme n'importe quelle autre colonne.
Pandas applique le calcul sur toutes les lignes en une seule instruction, sans avoir besoin d'une boucle for.
C'est ce qu'on appelle une transformation vectorielle : c'est rapide et concis.
bool)On peut créer une colonne dont les valeurs sont True ou False en appliquant une condition sur une colonne existante.
Ces colonnes booléennes sont particulièrement utiles pour filtrer ensuite.
Comparaison simple :
df["is_dinner"] = df["time"] == "Dinner"
Comparaison numérique :
df["is_generous"] = df["tip"] > 5
Comparaison avec une liste de valeurs (.isin()) :
df["is_weekend"] = df["day"].isin(["Sun", "Sat"])
Pour visualiser le résultat, on peut afficher les premières lignes avec les colonnes concernées :
print(df[["time", "tip", "day", "is_dinner", "is_generous", "is_weekend"]].head())
Résultat :
time tip day is_dinner is_generous is_weekend
0 Dinner 1.01 Sun True False True
1 Dinner 1.66 Sun True False True
2 Dinner 3.50 Sun True False True
3 Dinner 3.31 Sun True False True
4 Dinner 3.61 Sun True False True
Résumé des colonnes créées :
| Colonne | Type | Description |
|---|---|---|
is_dinner | bool | Vrai si le repas est un souper |
is_generous | bool | Vrai si le pourboire dépasse 5 $ |
is_weekend | bool | Vrai si le jour est samedi ou dimanche |
.isin() vs ==== compare à une seule valeur. .isin([...]) compare à plusieurs valeurs à la fois et est l'équivalent d'un or sur plusieurs ==.
Une fois créées, tip_percentage, is_generous, is_weekend et is_dinner sont disponibles dans df comme n'importe quelle colonne existante. On peut les utiliser pour filtrer, trier, sélectionner ou visualiser, exactement comme on le ferait avec tip ou day.
La méthode map() permet de remplacer chaque valeur d'une colonne par la valeur correspondante dans un dictionnaire.
C'est utile pour convertir des codes en noms lisibles, des abréviations en texte complet, etc.
df_cryptos = pd.DataFrame({
"symbole": ["BTC", "ETH", "SOL", "ADA", "XRP", "DOT"],
"valeur_courante": [94406.0, 3101.57, 137.55, 0.4854, 2.22, 2.80]
})
dict_symboles_noms = {
"BTC": "Bitcoin",
"ETH": "Ethereum",
"SOL": "Solana",
"ADA": "Cardano",
"XRP": "Ripple",
"DOT": "Polkadot"
}
df_cryptos["nom"] = df_cryptos["symbole"].map(dict_symboles_noms)
print(df_cryptos.head())
Résultat :
symbole valeur_courante nom
0 BTC 94406.0000 Bitcoin
1 ETH 3101.5700 Ethereum
2 SOL 137.5500 Solana
3 ADA 0.4854 Cardano
4 XRP 2.2200 Ripple
map() regarde chaque valeur de symbole, cherche la clé correspondante dans le dictionnaire, et retourne une nouvelle colonne avec les noms complets.
Si une valeur de la colonne n'est pas présente comme clé dans le dictionnaire, Pandas la remplace silencieusement par NaN. On s'assure que le dictionnaire couvre toutes les valeurs possibles, ou on vérifie après coup avec df["col"].isnull().sum().
np.where() vs Pandas : deux façons de faire la même choseOn connaît déjà np.where() de la rencontre 10. En Pandas, on peut faire exactement la même opération avec np.where() directement sur une colonne, ou avec apply() :
import numpy as np
# Avec np.where() (qu'on connaît déjà de NumPy)
df["categorie"] = np.where(df["tip"] > 5, "généreux", "normal")
# Avec apply() + lambda (façon Pandas)
df["categorie"] = df["tip"].apply(lambda x: "généreux" if x > 5 else "normal")
Les deux produisent le même résultat. np.where() est plus rapide sur de grands jeux de données; apply est plus lisible pour des conditions complexes.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Créer une colonne (calcul) | df["col"] = df["a"] + df["b"] | Nouvelle colonne par calcul |
| Créer une colonne (comparaison) | df["col"] = df["a"] > 5 | Nouvelle colonne booléenne |
| Créer une colonne (liste) | df["col"] = df["a"].isin([...]) | Vrai si la valeur est dans la liste |
| Convertir un type | df["col"] = df["col"].astype(float) | Change le type de la colonne |
| Mapper un dictionnaire | df["col"] = df["a"].map(dict) | Remplace les valeurs via un dictionnaire |
Les explications de cette section étaient-elles claires ?
Cet onglet couvre deux niveaux d’analyse : les statistiques sur une colonne (moyenne, somme, valeurs uniques) et les statistiques par groupe avec groupby(). L’idée est toujours la même : résumer les données pour en dégager des tendances.
Les exemples qui suivent utilisent le fichier tips_dataset.csv chargé dans un DataFrame df :
import pandas as pd
df = pd.read_csv("tips_dataset.csv")
On peut appeler des méthodes statistiques directement sur une colonne (une Series). Voici les essentielles à connaître :
On connaît déjà np.mean(), np.min(), np.max() de la rencontre 10. En Pandas, ces mêmes opérations s'appellent directement sur la colonne : df["col"].mean() plutôt que np.mean(tableau). Le résultat est identique, seule la syntaxe change.
print(df["tip"].mean()) # → 2.998... (moyenne)
print(df["tip"].sum()) # → 731.58 (somme)
print(df["tip"].min()) # → 1.0 (minimum)
print(df["tip"].max()) # → 10.0 (maximum)
print(df["tip"].median()) # → 2.9 (médiane)
print(df["tip"].count()) # → 244 (nombre de valeurs non-nulles)
L’écart-type std() et la variance var() mesurent la dispersion des données autour de la moyenne. Utiles en statistiques, mais moins prioritaires pour débuter.
Pour une colonne textuelle, plutôt que des moyennes, on veut savoir quelles valeurs existent et combien de fois elles apparaissent.
Lister les valeurs distinctes et leur fréquence :
print(df["day"].value_counts())
Résultat :
day
Sat 87
Sun 76
Thur 62
Fri 19
Name: count, dtype: int64
value_counts() retourne les valeurs triées du plus fréquent au moins fréquent. C’est souvent la première chose à faire sur une colonne textuelle.
Lister les valeurs uniques et en compter le nombre :
print(df["day"].unique()) # → [‘Sun’ ‘Sat’ ‘Thur’ ‘Fri’]
print(df["day"].nunique()) # → 4
On constate qu’il n’y a que 4 jours dans le jeu de données : lundi, mardi et mercredi sont absents.
nunique() vs unique()nunique() ne compte pas les NaN, alors que unique() les inclut dans la liste.
groupby()groupby() permet de diviser le DataFrame en groupes selon les valeurs d’une colonne, puis d’appliquer une fonction statistique sur chaque groupe.
Pandas suit trois étapes : il sépare les lignes en groupes, applique une fonction sur chacun, puis combine les résultats en une Series ou un DataFrame.
Exemple — pourboire moyen par jour :
tip_par_jour = df.groupby("day")["tip"].mean()
print(tip_par_jour)
Résultat : (une Series)
day
Fri 2.734737
Sat 2.993103
Sun 3.255132
Thur 2.771452
Name: tip, dtype: float64
La colonne de regroupement (day) devient l’index du résultat (Fri, Sat, ...), et les valeurs sont les statistiques calculées par groupe (2.734737, 2.993103, ...).
Plusieurs statistiques à la fois avec agg() :
df_stats = df.groupby("day")["tip"].agg(["mean", "sum", "count"])
print(df_stats)
Résultat : (un DataFrame, avec une colonne par statistique)
mean sum count
day
Fri 2.734737 51.96 19
Sat 2.993103 260.40 87
Sun 3.255132 247.39 76
Thur 2.771452 171.83 62
On peut aussi regrouper selon plusieurs colonnes, ici sex et day, puis calculer plusieurs statistiques, ici mean et count, sur plusieurs colonnes numériques, ici tip et total_bill :
df.groupby(["sex", "day"])[["tip", "total_bill"]].agg(["mean", "count"])
Cela produit un DataFrame avec un index hiérarchique sur les lignes (sex, puis day) et des colonnes hiérarchiques (tip/total_bill, puis mean/count).
Résultat possible :
tip total_bill
mean count mean count
sex day
Female Fri 2.781111 9 14.145556 9
Sat 2.801786 28 19.680357 28
Sun 3.367222 18 19.872222 18
Thur 2.575625 32 16.715312 32
Male Fri 2.693000 10 19.857000 10
Sat 3.083898 59 20.802542 59
Sun 3.220345 58 21.887241 58
Thur 2.980333 30 18.714667 30
Par exemple, la ligne Female / Fri donne les statistiques des factures du vendredi pour les clientes identifiées comme Female.
Utile pour des analyses croisées, mais la lecture du résultat est plus complexe.
pivot_table() ressemble à groupby(), mais organise les résultats en tableau à deux dimensions pour faciliter la comparaison visuelle.
On choisit ce qui va sur les lignes, ce qui va sur les colonnes, et quelle valeur on calcule dans les cellules.
df_pivot = df.pivot_table(
values="tip", # valeur à calculer
index="size", # regroupement sur les lignes
columns="day", # regroupement sur les colonnes
aggfunc="mean" # fonction statistique
)
print(df_pivot)
Résultat :
day Fri Sat Sun Thur
size
1 1.000000 2.000000 1.500000 NaN
2 2.250000 2.592857 3.070588 2.428571
3 3.000000 3.622222 3.050000 2.250000
4 1.500000 3.500000 4.030303 3.683333
5 NaN 2.750000 4.566667 2.600000
6 NaN 5.000000 NaN 5.300000
Chaque cellule contient le pourboire (tip) moyen (mean) pour une taille de groupe (size) et un jour (day) donnés. Les NaN indiquent qu’aucune donnée n’existe pour cette combinaison.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Moyenne | moyenne = df["col"].mean() | Moyenne des valeurs |
| Somme | somme = df["col"].sum() | Somme des valeurs |
| Minimum / Maximum | minimum = df["col"].min() | Valeur minimale ou maximale |
| Médiane | mediane = df["col"].median() | Valeur médiane |
| Nombre de valeurs | nb_valeurs = df["col"].count() | Valeurs non-nulles |
| Fréquences | frequences = df["col"].value_counts() | Fréquence de chaque valeur |
| Valeurs uniques | uniques = df["col"].unique() | Liste des valeurs distinctes |
| Nombre de valeurs uniques | nb_uniques = df["col"].nunique() | Nombre de valeurs distinctes |
| Grouper + statistique | df_groupe = df.groupby("col")["val"].mean() | Statistique par groupe |
| Grouper + plusieurs stats | df_groupe = df.groupby("col")["val"].agg([...]) | Plusieurs stats par groupe |
| Table de pivot | df_pivot = df.pivot_table(values=..., index=..., columns=...) | Tableau croisé de statistiques |
Les explications de cette section étaient-elles claires ?
Une fois les données nettoyées, transformées ou analysées, on veut souvent les sauvegarder pour les réutiliser ailleurs : les partager avec un collègue, les intégrer dans une autre application. Pandas permet d'exporter un DataFrame en quelques lignes.
Les exemples qui suivent utilisent le fichier tips_dataset.csv chargé et transformé dans un DataFrame df :
import pandas as pd
df = pd.read_csv("tips_dataset.csv")
df["tip_percentage"] = (df["tip"] / df["total_bill"]) * 100
On prépare d'abord le DataFrame à exporter en enchaînant les manipulations souhaitées. Ici, on filtre les repas du soir avec un pourboire supérieur à 15 % et on trie par pourcentage décroissant :
df_export = df[(df["time"] == "Dinner") & (df["tip_percentage"] > 15)].sort_values("tip_percentage", ascending=False)
df_export est maintenant prêt à être sauvegardé dans le format de son choix.
Le format CSV est le plus universel : lisible par Excel, Python, R, et la plupart des outils d'analyse.
df_export.to_csv("soupers_genereux.csv", index=False)
Le fichier soupers_genereux.csv est créé dans le même dossier que le script.
index=FalsePar défaut, Pandas ajoute une colonne d'index (0, 1, 2...) au début du fichier. index=False évite cette colonne, souvent inutile dans un fichier CSV destiné à être lu par d'autres outils.
| Opération | Syntaxe | Description |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Exporter en CSV | df.to_csv("fichier.csv", index=False) | Fichier CSV sans colonne d'index |
Les explications de cette section étaient-elles claires ?
Pandas s'intègre directement avec Matplotlib pour générer des graphiques à partir d'un DataFrame.
On importe les deux bibliothèques, on charge les données, et on trace en quelques lignes seulement.
Pour se rafraîchir la mémoire sur Matplotlib, on peut consulter l'onglet Matplotlib de la rencontre 9.
Pour aller plus loin, on peut aussi consulter la documentation officielle de Matplotlib.
Les exemples qui suivent utilisent le fichier tips_dataset.csv chargé dans un DataFrame df, avec une colonne calculée tip_percentage :
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("tips_dataset.csv")
df["tip_percentage"] = (df["tip"] / df["total_bill"]) * 100
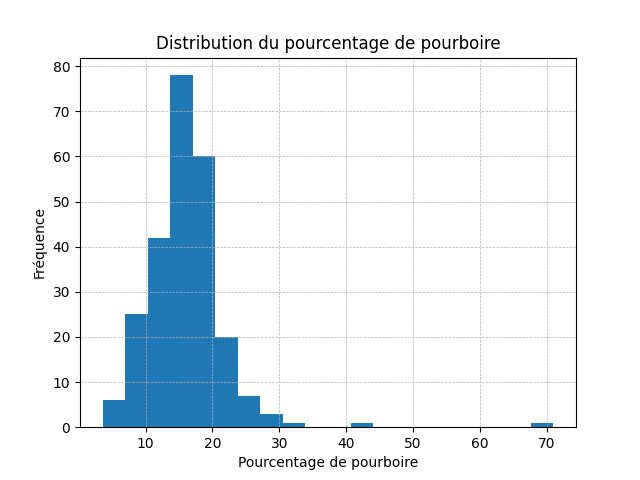
Un histogramme montre comment les valeurs d'une colonne sont réparties (sa distribution). L'axe des X est divisé en intervalles de valeurs, et l'axe Y indique combien de données tombent dans chaque intervalle. Le paramètre bins détermine le nombre d'intervalles. Pandas calcule automatiquement la largeur de chaque intervalle en divisant l'écart entre la valeur minimale et maximale par le nombre de bins :
largeur d'un intervalle = (max − min) / bins
Par exemple, si tip_percentage va de 3 % à 71 % et qu'on demande bins=20, chaque intervalle aura une largeur d'environ (71 − 3) / 20 ≈ 3,4 %.
df["tip_percentage"].hist(
bins=20 # diviser en 20 intervalles
)
plt.title("Distribution du pourcentage de pourboire")
plt.xlabel("Pourcentage de pourboire (%)")
plt.ylabel("Fréquence")
plt.grid(axis='both', linestyle='--', linewidth=0.5)
plt.show()
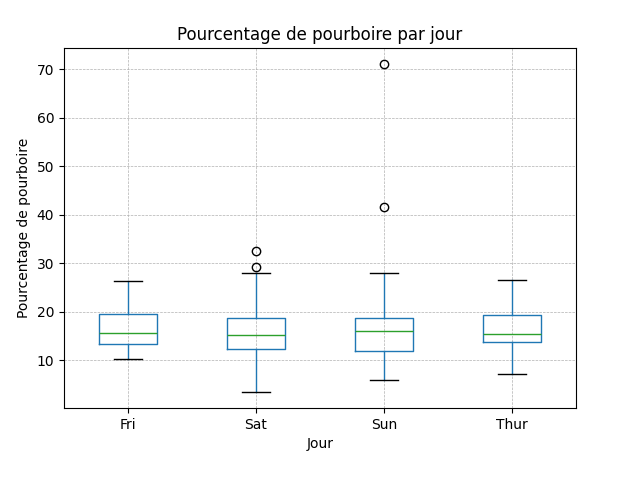
Une boîte à moustaches (boxplot) montre la distribution d'une variable numérique pour chaque groupe. Voici comment lire chaque élément du graphique :
Comment interpréter une boîte à moustaches :
- La ligne du milieu (orange) représente la médiane : 50 % des valeurs sont en dessous, 50 % au-dessus.
- Le bas de la boîte représente le 1er quartile (Q1) : 25 % des valeurs sont en dessous.
- Le haut de la boîte représente le 3e quartile (Q3) : 75 % des valeurs sont en dessous.
- La hauteur de la boîte est l'intervalle interquartile (IQR) = Q3 − Q1 : il contient le 50 % central des données.
- Les moustaches (les traits) s'étendent jusqu'à 1,5 × IQR au-delà de Q1 et Q3.
- Les cercles (•) sont les valeurs aberrantes (outliers) : valeurs qui dépassent les moustaches.
df.boxplot(
column="tip_percentage", # axe des y
by="day" # regroupement (axe des x)
)
plt.title("Pourcentage de pourboire par jour")
plt.suptitle("") # retire le titre autogénéré
plt.xlabel("Jour")
plt.ylabel("Pourcentage de pourboire (%)")
plt.grid(axis='both', linestyle='--', linewidth=0.5)
plt.show()
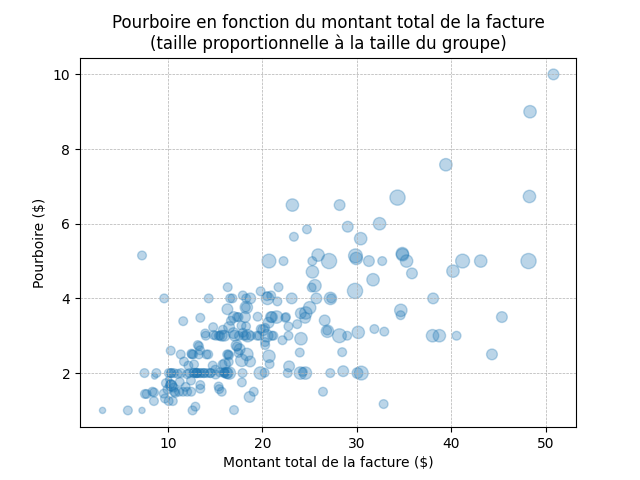
Un nuage de points (scatter plot) montre la relation entre deux variables numériques. On peut ajouter une troisième variable en faisant varier la taille des points.
plt.scatter(
x=df["total_bill"], # axe des x
y=df["tip"], # axe des y
s=df["size"] * 20, # taille des points
# (×20 pour la visibilité)
alpha=0.5 # opacité
)
plt.xlabel("Montant total de la facture ($)")
plt.ylabel("Pourboire ($)")
plt.title("Pourboire en fonction du montant " +
"total de la facture\n" +
"(taille ∝ nombre de convives)")
plt.grid(axis='both', linestyle='--', linewidth=0.5)
plt.show()
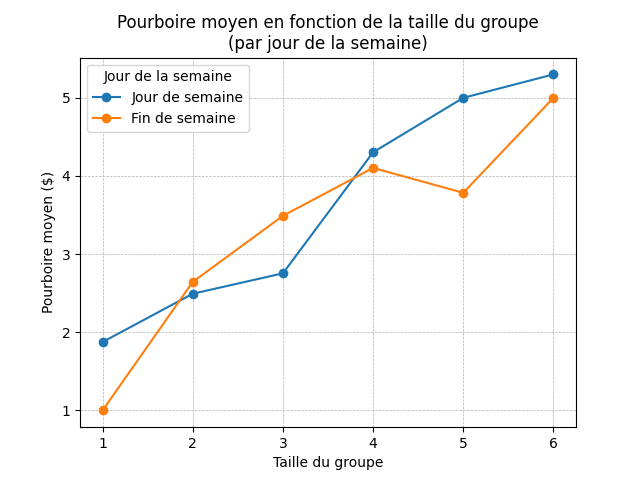
En combinant pivot_table() et .plot(), on peut tracer plusieurs courbes sur un même graphique pour comparer des tendances selon une variable catégorielle.
df["is_weekend"] = df["day"].isin(["Sun", "Sat"])
df_pivot = df.pivot_table(
values="tip", # axe des y
index="size", # axe des x
columns="is_weekend", # une courbe par groupe
aggfunc="mean"
)
df_pivot.plot(marker="o")
plt.xlabel("Taille du groupe")
plt.ylabel("Pourboire moyen ($)")
plt.title("Pourboire en fonction " +
"de la taille du groupe\n" +
"(par jour de la semaine)")
plt.legend(
title="Jour de la semaine",
labels=["Jour de semaine", "Fin de semaine"]
)
plt.grid(axis='both', linestyle='--', linewidth=0.5)
plt.show()
| Graphique | Syntaxe | Usage |
|---|---|---|
| Importer Pandas | import pandas as pd | Convention universelle |
| Importer Matplotlib | import matplotlib.pyplot as plt | Convention universelle |
| Histogramme | df["col"].hist(bins=20) | Distribution d'une colonne numérique |
| Boîte à moustaches | df.boxplot(column="col", by="groupe") | Distribution par groupe |
| Nuage de points | plt.scatter(x=df["x"], y=df["y"]) | Relation entre deux variables |
| Courbes groupées | df.pivot_table(...).plot() | Tendances par groupe |
| Afficher | plt.show() | Afficher le graphique |
Les explications de cette section étaient-elles claires ?
Pour favoriser une progression efficace, ce cours adopte une approche de classe inversée. Ce modèle déplace l'acquisition théorique hors de la classe pour transformer les heures de rencontre en véritables séances d'application pratique.
-
À la maison (Exploration et Appropriation) : Vous êtes le maître de votre rythme. Ces activités vous permettent de découvrir les nouveaux concepts et tester les exemples au moment où vous êtes le plus concentré. Si une notion vous semble obscure, n'hésitez pas à poser des questions à votre prof au fur et à mesure.
-
En classe (Application et Consolidation) : Le temps en présentiel est une ressource précieuse. Nous l'utilisons pour nous attaquer aux défis plus complexes et aux exercices de programmation qui demandent une mobilisation active de vos connaissances. C’est le moment idéal pour obtenir une rétroaction immédiate, collaborer avec vos pairs et bénéficier de l'accompagnement de votre enseignant au moment où vous en avez le plus besoin.
- 🏠 Activités à faire à la maison
- 🏫 Activités à faire en classe
🧠 Auto-validation des connaissances
Ce formulaire sert à vérifier votre compréhension des éléments les plus importants de la rencontre R11. Ne faites ce questionnaire que lorsque vous vous sentez en très bonne maîtrise de la matière. En classe, dès votre arrivée, vous aurez un questionnaire très similaire, évalué sommativement, à compléter sans accès à aucune documentation.
Ne pas remplir le formulaire diminue fortement vos chances de réussir l’évaluation sommative en début de rencontre.
Assurez-vous de bien comprendre toutes les notions derrière chaque question.
🔨 Exercices de création
Pour chacun des exercices de cette section, vous devez créer des fichiers .py avec les noms indiqués.
Pour les exercices de cette section, vous pouvez consulter librement la documentation du site web du cours.
📁 Créez un fichier r11_modeles_vehicules.py pour votre réponse.
Téléchargez le fichier mpg_dataset.csv et placez-le dans le même dossier que votre script.
Exploration
- Chargez les données dans un DataFrame.
- Affichez le résumé technique avec
info()(types, valeurs manquantes, taille). - Affichez les types de données de chaque colonne avec
dtypes. - Affichez les statistiques descriptives avec
describe().
Résultat attendu pour dtypes :
mpg float64
cylinders int64
displacement float64
horsepower float64
weight int64
acceleration float64
model_year int64
origin object
name object
dtype: object
Résultat attendu pour describe() :
mpg cylinders displacement horsepower weight acceleration model_year
count 398.000000 398.000000 398.000000 392.000000 398.000000 398.000000 398.000000
mean 23.514573 5.454774 193.425879 104.469388 2970.424623 15.568090 76.010050
std 7.815984 1.701004 104.269838 38.491160 846.841774 2.757689 3.697627
min 9.000000 3.000000 68.000000 46.000000 1613.000000 8.000000 70.000000
25% 17.500000 4.000000 104.250000 75.000000 2223.750000 13.825000 73.000000
50% 23.000000 4.000000 148.500000 93.500000 2803.500000 15.500000 76.000000
75% 29.000000 8.000000 262.000000 126.000000 3608.000000 17.175000 79.000000
max 46.600000 8.000000 455.000000 230.000000 5140.000000 24.800000 82.000000
Filtrage et tri
- Filtrez et affichez les modèles japonais ayant une accélération de 19.4 et plus.
Résultat attendu :
Les modèles japonais ayant une accélération de 19.4 et plus :
- toyota corolla 1200
- mazda glc deluxe
- datsun 210 mpg
- Filtrez et affichez les 5 voitures avec le plus de horsepower.
Résultat attendu :
Les 5 voitures avec le plus de horsepower :
- horsepower : 230.0 - pontiac grand prix
- horsepower : 225.0 - buick electra 225 custom
- horsepower : 225.0 - pontiac catalina
- horsepower : 225.0 - buick estate wagon (sw)
- horsepower : 220.0 - chevrolet impala
Comptage
- Affichez le nombre de voitures japonaises avec un poids supérieur à 2500.
Résultat attendu :
Le nombre de voitures japonaises avec un poids supérieur à 2500 : 17
Exportation
- Filtrez le DataFrame pour ne conserver que les voitures japonaises, puis exportez ce nouveau DataFrame dans un fichier nommé
mpg_japonaises.csvsans l'index. Ouvrez ensuite le fichier dans un éditeur ou un tableur pour vérifier qu'il ne contient bien que des voitures japonaises.
Pandas, chargement CSV read_csv(), info(), dtypes, describe(), filtrage booléen, tri sort_values(), comptage, exportation to_csv()
📁 Créez un fichier r11_prix_turing.py pour votre réponse.
Téléchargez le fichier Turing.csv et placez-le dans le même dossier que votre script. Il contient tous les gagnants du Prix Turing.
Exploration
- Chargez les données dans un DataFrame.
- Affichez le nombre de lignes et de colonnes du DataFrame ainsi que la liste de ses colonnes.
Résultat attendu :
Dimensions : (79, 4)
Colonnes : ['year', 'laureate', 'contribution', 'affiliation']
Comptage
- Affichez le nombre total de lauréats.
Résultat attendu :
Nombre total de lauréats : 79
Filtrage
- Affichez les lauréats dont la contribution contient le mot
'intelligence'.
Résultat attendu :
Lauréats avec 'intelligence' dans la contribution :
- Marvin Minsky
- Allen Newell
- Herbert A. Simon
- Raj Reddy
- Affichez les lauréats affiliés à MIT ou Stanford.
Résultat attendu :
Lauréats affiliés à MIT ou Stanford :
- Marvin Minsky (MIT)
- John McCarthy (Stanford University)
- Donald E. Knuth (Stanford University)
- Robert W. Floyd (Stanford University)
- Fernando J. Corbató (MIT)
- Edward A. Feigenbaum (Stanford University)
- Douglas C. Engelbart (Stanford Research Institute (SRI))
- Ronald L. Rivest (MIT)
- Barbara H. Liskov (MIT)
- Shafi Goldwasser (MIT / Weizmann Institute)
- Silvio Micali (MIT)
- Michael Stonebraker (MIT)
- Whitfield Diffie (Stanford / Sun Microsystems)
- Martin E. Hellman (Stanford University)
- Tim Berners-Lee (CERN / W3C / MIT)
- John L. Hennessy (Stanford University)
- Patrick M. Hanrahan (Stanford University / Pixar)
- Jeffrey D. Ullman (Stanford University)
- Affichez les lauréats ayant reçu le prix entre 1980 et 1990 inclusivement.
Résultat attendu :
Lauréats entre 1980 et 1990 :
- 1980 : C.A.R. (Tony) Hoare
- 1981 : Edgar F. Codd
- 1982 : Stephen A. Cook
- 1983 : Kenneth L. Thompson
- 1983 : Dennis M. Ritchie
- 1984 : Niklaus Wirth
- 1985 : Richard M. Karp
- 1986 : John E. Hopcroft
- 1986 : Robert E. Tarjan
- 1987 : John Cocke
- 1988 : Ivan E. Sutherland
- 1989 : William (Velvel) Kahan
- 1990 : Fernando J. Corbató
- Affichez les 5 lauréats les plus récents.
Résultat attendu :
Les 5 lauréats les plus récents :
- 2024 : Richard S. Sutton
- 2024 : Andrew G. Barto
- 2023 : Avi Wigderson
- 2022 : Robert M. Metcalfe
- 2021 : Jack J. Dongarra
Statistiques
-
Créez une nouvelle colonne
decennieen appliquant la formule(year // 10) * 10utilisant la colonneyear(ex. 1986 → 1980, 2023 → 2020). -
Affichez le nombre de lauréats par décennie. (indice : regroupement + compte)
Résultat attendu :
Lauréats par décennie :
- 1960s : 4 lauréats
- 1970s : 12 lauréats
- 1980s : 12 lauréats
- 1990s : 12 lauréats
- 2000s : 16 lauréats
- 2010s : 16 lauréats
- 2020s : 7 lauréats
Pandas, dimensions (shape), liste des colonnes, filtrage par texte str.contains(), conditions multiples (|), tri, création de nouvelle colonne, regroupement groupby() et comptage
📁 Créez un fichier r11_groupby_moyenne.py pour votre réponse.
Téléchargez le fichier tips_dataset.csv et placez-le dans le même dossier que votre script.
- Chargez les données dans un DataFrame.
- Calculez et affichez la facture moyenne (
total_bill) par jour de la semaine.
Résultat attendu :
day
Fri 17.151579
Sat 20.441379
Sun 21.410000
Thur 17.682742
Name: total_bill, dtype: float64
- Calculez et affichez le total des pourboires (
tip) par moment de la journée (dîner/lunch).
Résultat attendu :
time
Dinner 546.07
Lunch 185.51
Name: tip, dtype: float64
- Calculez et affichez la taille moyenne du groupe (
size) par jour de la semaine.
Résultat attendu :
day
Fri 2.105263
Sat 2.517241
Sun 2.842105
Thur 2.451613
Name: size, dtype: float64
- Calculez et affichez le nombre de repas par sexe (
sex).
Résultat attendu :
sex
Female 87
Male 157
Name: total_bill, dtype: int64
- Calculez et affichez la facture moyenne par statut fumeur (
smoker).
Résultat attendu :
smoker
No 19.188278
Yes 20.756344
Name: total_bill, dtype: float64
En observant ces résultats, répondez aux questions suivantes :
- Quel jour de la semaine génère les factures les plus élevées? Et le plus faibles?
- Le dîner ou le lunch génère-t-il plus de pourboires au total? Pourquoi selon vous?
- Est-ce que les fumeurs dépensent plus en moyenne que les non-fumeurs?
- Quel jour vient-on en plus grand groupe? Est-ce cohérent avec la facture moyenne de ce jour?
- Les hommes ou les femmes viennent-ils manger plus souvent au restaurant?
Pandas, regroupement groupby(), fonctions d'agrégation (mean, sum, count), interprétation de résultats
📁 Créez un fichier r11_nettoyage_selection.py pour votre réponse.
Un registraire de cégep dispose d'un tableau d'étudiants en Sciences de la nature contenant des données manquantes et des doublons. Les programmes sont :
- 200.BA : Sciences de la santé
- 200.BB : Sciences pures et appliquées
- 200.BC : Sciences de la nature (Découverte / Enrichi)
Utilisez le dictionnaire suivant pour créer votre DataFrame :
import pandas as pd
data = {
'prenom': ['Léa', 'Mathis', 'Léa', 'Yasmine', 'Tristan', None, 'Émile'],
'programme': ['200.BA', '200.BB', '200.BA', '200.BC', '200.BA', '200.BB', '200.BC'],
'session': [3, None, 3, 2, None, 4, 1],
'note_finale': [78, 85, 78, None, 91, 67, None],
'nb_absences': [2, 0, 2, 5, None, 1, 3]
}
df = pd.DataFrame(data)
Le DataFrame initial ressemble à ceci :
prenom programme session note_finale nb_absences
0 Léa 200.BA 3.0 78.0 2.0
1 Mathis 200.BB NaN 85.0 0.0
2 Léa 200.BA 3.0 78.0 2.0
3 Yasmine 200.BC 2.0 NaN 5.0
4 Tristan 200.BA NaN 91.0 NaN
5 NaN 200.BB 4.0 67.0 1.0
6 Émile 200.BC 1.0 NaN 3.0
Nettoyage
- Affichez les lignes ne contenant aucune valeur manquante.
Résultat attendu :
prenom programme session note_finale nb_absences
0 Léa 200.BA 3.0 78.0 2.0
2 Léa 200.BA 3.0 78.0 2.0
- Remplacez les valeurs manquantes comme suit, puis affichez le DataFrame corrigé :
session: remplacez par la moyenne des sessionsnote_finale: remplacez par la médiane des notesnb_absences: remplacez par0
Résultat attendu :
prenom programme session note_finale nb_absences
0 Léa 200.BA 3.0 78.0 2.0
1 Mathis 200.BB 2.6 85.0 0.0
2 Léa 200.BA 3.0 78.0 2.0
3 Yasmine 200.BC 2.0 78.0 5.0
4 Tristan 200.BA 2.6 91.0 0.0
5 NaN 200.BB 4.0 67.0 1.0
6 Émile 200.BC 1.0 78.0 3.0
Continuez avec ce DataFrame corrigé pour les étapes suivantes.
- Supprimez les lignes dupliquées et affichez le DataFrame résultant.
Résultat attendu :
prenom programme session note_finale nb_absences
0 Léa 200.BA 3.0 78.0 2.0
1 Mathis 200.BB 2.6 85.0 0.0
3 Yasmine 200.BC 2.0 78.0 5.0
4 Tristan 200.BA 2.6 91.0 0.0
5 NaN 200.BB 4.0 67.0 1.0
6 Émile 200.BC 1.0 78.0 3.0
Sélection
- À partir du DataFrame corrigé (avant suppression des doublons), affichez le prénom et la note finale des étudiants en 200.BA (Sciences de la santé).
Résultat attendu :
prenom note_finale
0 Léa 78.0
2 Léa 78.0
4 Tristan 91.0
- Affichez les 3 premières lignes et les colonnes
prenom,programmeetsessiondu DataFrame corrigé.
Résultat attendu :
prenom programme session
0 Léa 200.BA 3.0
1 Mathis 200.BB 2.6
2 Léa 200.BA 3.0
Création d'un DataFrame depuis un dictionnaire, valeurs manquantes dropna(), fillna(), mean/median, suppression de doublons drop_duplicates(), sélection de colonnes et de lignes loc, iloc, head()
📁 Créez un fichier r11_pourboire_par_personne.py pour votre réponse.
Téléchargez le fichier tips_dataset.csv et placez-le dans le même dossier que votre script.
Transformation
- Chargez les données dans un DataFrame.
- Créez une nouvelle colonne
tip_par_personqui calcule le pourboire par personne (tipdivisé parsize). - Affichez les 5 premières lignes du DataFrame modifié.
Résultat attendu :
total_bill tip sex smoker day time size tip_par_person
0 16.99 1.01 Female No Sun Dinner 2 0.505000
1 10.34 1.66 Male No Sun Dinner 3 0.553333
2 21.01 3.50 Male No Sun Dinner 3 1.166667
3 23.68 3.31 Male No Sun Dinner 2 1.655000
4 24.59 3.61 Female No Sun Dinner 4 0.902500
Visualisation
- Générez un histogramme de
tip_par_personavecbins=10pour visualiser la distribution des pourboires par personne. - Générez un boxplot de
tip_par_personregroupé par taille de groupe (size) pour voir comment le pourboire par personne varie selon la taille du groupe.
Résultats attendus :
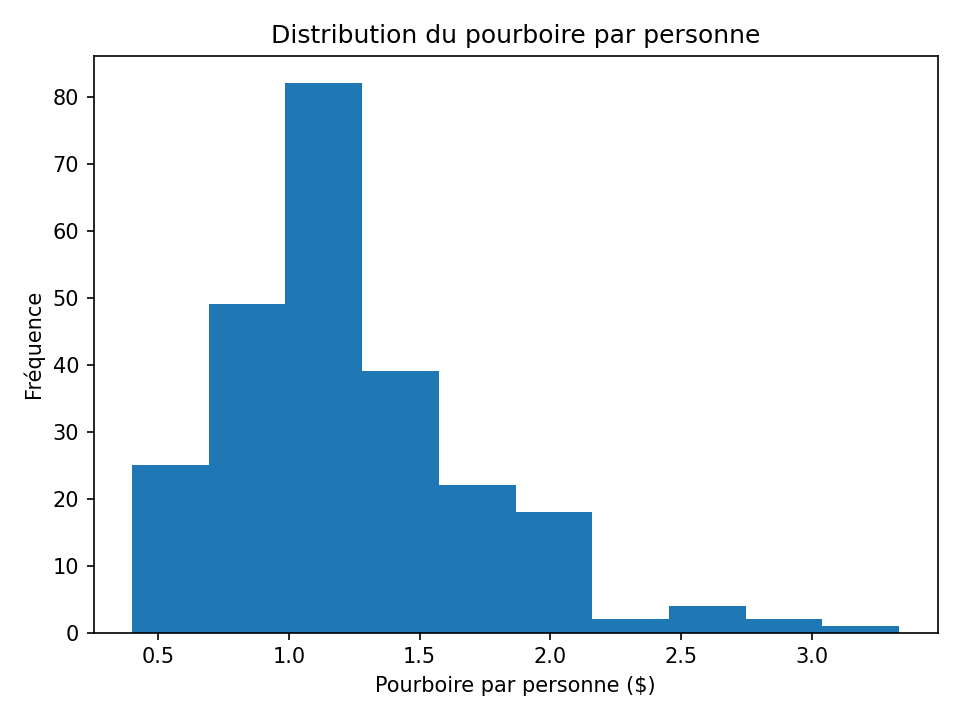
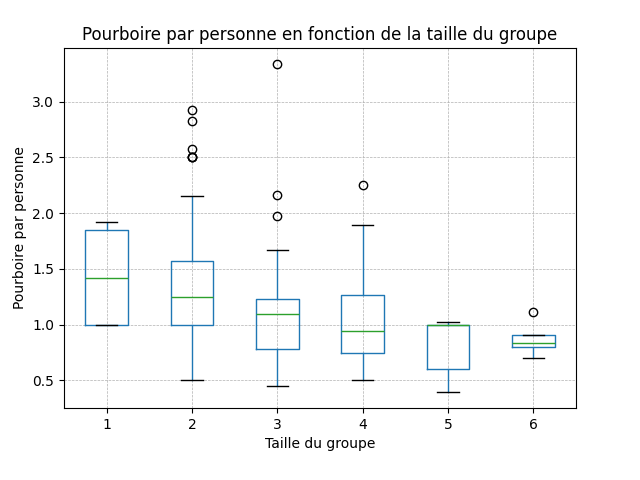
Voyez-vous des tendances intéressantes ? Par exemple, est-ce que le pourboire par personne augmente ou diminue avec la taille du groupe?
Pandas, création de colonne calculée, head(), visualisation (histogramme avec bins, boxplot par groupe)
✏️ Exercices sur papier
Les exercices suivants ne visent pas nécessairement à pratiquer la matière de cette rencontre,
mais plutôt à vous entraîner à l'écriture de code "papier" sur des concepts plus simples, comme il pourrait y avoir à l'examen.
Faites ces exercices d'abord sur papier (ou dans un éditeur de texte simple) et sans aucune documentation, comme à l'examen.
Vous pouvez valider votre réponse dans PyCharm à la fin — un luxe que vous n'aurez pas le jour de l'examen, d'où l'importance de vous entraîner sans lui.
Sur papier, sans ordinateur, écrivez un code demandant à l'utilisateur de saisir un nombre.
Tant que le nombre saisi est positif, le programme redemande de saisir un nouveau nombre.
Lorsqu'un nombre saisi est négatif, le programme affiche tous les nombres saisis ainsi que leur somme.
Le programme prend alors fin.
Exemple d'exécution
Saisir un nombre : 20
Saisir un nombre : 50
Saisir un nombre : 10
Saisir un nombre : -5
Nombres saisis : [20, 50, 10, -5]
Somme : 75
📁 Créez un fichier r11_sans_pycharm.py pour valider votre réponse à l'aide de Pycharm.
Boucle while, saisie utilisateur input(), accumulation dans une liste, calcul de somme
🎯 Solutions des exercices
Un solutionnaire possible pour chaque exercice est disponible en format vidéo avec des explications. Vous pouvez vous en servir pour comparer votre solution avec une solution possible jugée optimale et vous débloquer après un long moment bloqué sur un exercice (ex. 20 minutes) et après avoir utilisé le débogueur pour essayer par vous-même de trouver le problème.
Il est tout à fait normal que certains problèmes demandent du temps, de la réflexion, et parfois même un peu de frustration. C’est précisément dans ces moments d’effort que l’apprentissage s’ancre réellement.
Consulter un solutionnaire avant d’avoir tenté l’exercice par soi-même, ou le parcourir trop rapidement, revient à court-circuiter le processus d’apprentissage. Ce n’est pas simplement contre-productif, c’est pédagogiquement désastreux.
En sautant l’étape de la réflexion personnelle, on prive son cerveau de l’occasion de construire des connexions durables. Et à force de répéter ce réflexe, on risque de passer à côté des compétences essentielles, ce qui peut mener à des échecs plus tard, même si tout semble facile sur le moment. Alors oui, prenez le temps. L’erreur fait partie du jeu. C’est en cherchant, en tâtonnant, en doutant, qu’on devient réellement compétent. Le solutionnaire doit être un outil de validation, pas un raccourci.
🔨 Solution des exercices de création :
- Analyse : Modèles de véhicules
- Analyse : Prix Turing
- groupby et moyenne
- Nettoyage et sélection de données
- Visualisation : Pourboire par personne
✏️ Solution des exercices sur papier :