🤖 TP2, Intelligence artificielle
- 🛠 TP2
- *🤖 Intelligence artificielle*
- *🧠🧮 Apprentissage machine*
- *🧠🕸️ Apprentissage profond*
- *🌳 Empreinte écologique*
- *🤖 Scikit-learn*
Cette période est dédiée à l'avancement de votre travail pratique 2.
Le TP2 compte pour 25% de la note finale et se divise en deux remises partielles : la première vaut 10% et la seconde 15%.
Les éléments évalués dans chacune des remises sont clairement indiqués dans l'énoncé.
Les remises doivent être complétées avant minuit à la date indiquée par votre enseignant.e.
Le prochain cours sera consacré au formatif de l'examen final.
Le code de votre dépôt Git sera automatiquement récupéré — aucune action de votre part n'est requise.
En cas d'annulation d'un cours, la période de travail supplémentaire sur le TP2 sera supprimée, la date de remise demeurera dans la 15e semaine.
L'intelligence artificielle (IA) est un domaine de l'informatique visant à créer des systèmes capables d'effectuer des tâches qui nécessitent normalement l'intelligence humaine, telles que la reconnaissance vocale, la vision par ordinateur, la prise de décision et le traitement du langage naturel.
Dans les dernières années, l'utilisation d'outils basés sur l'IA, comme les modèles de langage (ex: ChatGPT), s'est largement démocratisée, rendant ces technologies accessibles à un public plus large. Cela a stimulé un intérêt accru pour l'IA et intensifié son développement. Cependant, cette popularisation a également permis de mieux comprendre les capacités et les limites de l'IA, tout en soulevant des questions éthiques et sociétales importantes.
Ça a été inventé hier, l'intelligence artificielle?
Non, pas vraiment!
L'IA a une histoire riche qui remonte aux années 1950, avec des avancées majeures dans les décennies suivantes. Voici un aperçu des principales étapes de son évolution :
| Période | Jalons | Idée dominante |
|---|---|---|
| 1950–1960 | Test de Turing, Dartmouth 1956 | Symbolisme, logique |
| 1970–1980 | Systèmes experts | Règles si-alors |
| 1990–2005 | Renaissance de l'apprentissage statistique | Données + optimisation |
| 2012–2020 | Explosion du deep learning (ImageNet) | Réseaux profonds |
| 2020+ | Modèles fondamentaux (LLM), efficience | Scalabilité, coût énergétique |
-
Pour la petite histoire, durant la Seconde Guerre mondiale, Alan Turing a développé des concepts fondamentaux en informatique et en cryptographie, afin de déchiffrer les codes ennemis des machines Enigma des Allemands. Après la guerre, il a proposé en 1950 un test pour évaluer l'intelligence d'une machine, et le terme intelligence artificielle a été officiellement introduit lors de la conférence de Dartmouth en 1956. Depuis, l'IA a connu des périodes d'enthousiasme et de scepticisme, mais elle est devenue un domaine central de la recherche informatique et de l'industrie technologique.
-
Les années 2010 ont vu exploser le deep learning grâce à la disponibilité de grandes quantités de données et à la puissance de calcul accrue, menant à des avancées spectaculaires en vision par ordinateur et en traitement du langage naturel. Aujourd'hui, l'IA continue d'évoluer rapidement, avec des applications dans presque tous les secteurs industriels.
-
En 2024, l'IA générative, notamment les modèles de langage comme GPT-4, a révolutionné la manière dont les machines interagissent avec les humains, ouvrant de nouvelles perspectives et défis pour l'avenir.
L'IA est utilisée dans de nombreux domaines pour automatiser des tâches, améliorer l'efficacité et offrir de nouvelles capacités. Voici quelques exemples notables :
| Domaine | Exemples |
|---|---|
| Vision | Reconnaissance d'objets, segmentation |
| Langage | Traduction, agents conversationnels |
| Santé | Aide diagnostique, imagerie |
| Sciences | Analyse données expérimentales |
| Énergie | Optimisation consommation |
L'IA soulève plusieurs enjeux éthiques importants, notamment :
- Biais et discrimination : Les modèles d'IA peuvent reproduire ou amplifier des biais présents dans les données d'entraînement, conduisant à des décisions injustes (ex: racisme, sexisme, etc.).
- Vie privée : L'utilisation de données personnelles pour entraîner des modèles d'IA peut compromettre la confidentialité des individus.
- Transparence : Les systèmes d'IA, en particulier les modèles complexes comme les réseaux de neurones profonds, peuvent être difficiles à interpréter, rendant leurs décisions opaques.
- Responsabilité : Déterminer qui est responsable des actions d'une IA, surtout en cas d'erreur ou de préjudice, est un défi juridique et éthique.
- Impact sur l'emploi : L'automatisation par l'IA peut entraîner des pertes d'emplois dans certains secteurs, nécessitant une réflexion sur la reconversion professionnelle et la formation.
Les explications de cette section étaient-elles claires ?
L'apprentissage machine (Machine Learning, ML) est une branche de l'intelligence artificielle qui se concentre sur le développement d'algorithmes et de modèles permettant aux ordinateurs d'apprendre à partir de données, sans être explicitement programmés pour chaque tâche spécifique. En utilisant des techniques statistiques, les modèles de ML identifient des patterns dans les données et font des prédictions ou prennent des décisions basées sur ces patterns.
Voici un diagramme qui présente les étapes clés d'un projet typique d'apprentissage machine, depuis la collecte des données brutes jusqu'à la génération de prédictions à l'aide d'un modèle entraîné :
📥 Données brutes
- Données collectées à partir de différentes sources : fichiers CSV, images, texte, etc.
- Elles sont souvent incomplètes, hétérogènes ou bruitées.
🧹 Prétraitement
- Nettoyage : valeurs manquantes, doublons, normalisation, encodage.
- Améliore la qualité des données et réduit l’erreur.
🧩 Extraction de caractéristiques
- Transformation des données en caractéristiques (features).
- Sélection d’attributs pertinents ou création de nouvelles variables.
🧠 Choix du modèle
- Choix de l’algorithme : régression, arbres de décision, forêts, réseaux de neurones, etc.
- Chaque modèle a ses forces et ses limites.
🎯 Entraînement
- Ajustement des paramètres du modèle pour minimiser l’erreur.
- Inclut souvent des itérations (epochs) et une validation.
- Peut être exigeant en ressources (temps, mémoire, énergie).
✅ Modèle entraîné
- Paramètres optimisés et structure fixe.
- Prêt à être évalué sur des données nouvelles.
📊 Évaluation
- Mesure de la performance sur un ensemble de test indépendant.
- Permet de valider la qualité réelle du modèle entraîné.
🚀 Prédictions
- Utilisation du modèle en contexte réel pour générer des prédictions.
- Intégration dans une application, un service ou un système automatisé.
L'entraînement est le processus par lequel un modèle d'apprentissage machine apprend à partir des données. Il consiste à ajuster les paramètres internes du modèle afin de minimiser une fonction de perte 📉 qui mesure l'écart entre les prédictions du modèle 🤖 et les valeurs réelles 🏷️.
Pour obtenir un modèle robuste et performant, l'entraînement nécessite souvent des ressources importantes :
- 📊 Données : Plus il y a de données de qualité, meilleur sera l'apprentissage.
- ⏱️ Temps de calcul : L'entraînement peut être long, surtout pour les modèles complexes.
- 💻 Puissance de calcul : Utilisation de GPU/TPU ⚡ pour accélérer les calculs.
- 🧠 Mémoire : Stockage des données et des paramètres du modèle pendant l'entraînement.
- 🔋 Énergie : Consommation énergétique importante liée au matériel informatique intensif.
Le surapprentissage se produit lorsqu'un modèle apprend trop bien les détails et le bruit des données d'entraînement, au point de perdre sa capacité à généraliser à de nouvelles données.
Ce concept peut sembler contre-intuitif 🤔 : comment un modèle peut-il être trop bon ?
Imaginez un étudiant qui mémorise par cœur chaque question d’un examen passé 📚🧠, sans comprendre réellement les concepts. Lorsqu’il est confronté à un nouvel examen avec des questions différentes ❓➡️❓, il échoue.
Le surapprentissage est similaire : le modèle performe exceptionnellement bien sur l’entraînement 💯, mais échoue sur des données jamais vues auparavant 🚫.
Pour éviter ce problème, plusieurs stratégies existent :
- 🛡️ Régularisation
- ⏳ Arrêt précoce (early stopping)
- 📂 Séparation des données en ensembles d'entraînement, validation et test
Pour prévenir le surapprentissage (overfitting), un jeu de données est généralement divisé en trois ensembles distincts, chacun ayant un rôle bien précis.
On pourrait par exemple utiliser la répartition classique 70% - 15% - 15% :
Les trois ensembles
- 📘 Entraînement (training set) Sert à apprendre : le modèle ajuste ses paramètres internes.
- 📙 Validation (validation set) Utilisé pour ajuster les hyperparamètres et surveiller le surapprentissage durant l’entraînement.
- 📗 Test (test set) Utilisé uniquement à la fin pour mesurer la performance réelle du modèle sur des données jamais vues.
Exemple pratique
Pour un jeu de 1000 échantillons 🧪 :
- 70% → 700 pour l’entraînement
- 15% → 150 pour la validation
- 15% → 150 pour le test
La séparation doit être faite aléatoirement 🎲 pour garantir que chaque ensemble reste représentatif.
Voici quelques algorithmes d'apprentissage machine couramment utilisés, classés par type :
| Type | Algorithmes | Description |
|---|---|---|
| Régression | Régression linéaire, régression logistique | Prédire une valeur continue ou une probabilité |
| Arbres de décision | CART, Random Forest, Gradient Boosting | Modèles basés sur des règles hiérarchiques |
| Machines à vecteurs de support | SVM | Trouver l'hyperplan optimal pour la classification |
| Réseaux de neurones | Perceptron, CNN, RNN | Modèles en couches pour données complexes |
| Clustering | K-means, DBSCAN | Regrouper des données non étiquetées en clusters |
Voici un exemple simple d'utilisation de la bibliothèque scikit-learn en Python pour effectuer une classification supervisée sur un vrai jeu de données classique : le jeu de données Iris (sklearn.datasets.load_iris).
Ce script suit les grandes étapes du pipeline vu plus haut : chargement des données → séparation entraînement/validation/test → entraînement → évaluation → prédictions.
Vous pouvez le rouler tel quel dans un environnement Python avec scikit-learn installé.
# 1. Import des bibliothèques nécessaires
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 2. Charger le jeu de données Iris
iris = load_iris()
X = iris.data # Caractéristiques (features) : mesures des fleurs
y = iris.target # Étiquettes (labels) : espèce d'Iris (0, 1 ou 2)
print("Noms des features :", iris.feature_names)
print("Noms des classes :", iris.target_names)
print("Taille du jeu de données :", X.shape, "échantillons\n")
# 3. Séparer les données en train / validation / test
# Ici, on commence par séparer en (train+val) et test,
# puis on re-sépare train+val en train et val.
# 15% des données pour le test final
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=0.15, random_state=42, stratify=y
)
# Sur le 85% restant, on garde 70% pour l'entraînement et 15% pour la validation
# 15% de 100% = 0.15 → 15% de 85% ≈ 17.6% → on ajuste la proportion
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=0.176, random_state=42, stratify=y_temp
)
print("Taille ensemble d'entraînement :", X_train.shape[0])
print("Taille ensemble de validation :", X_val.shape[0])
print("Taille ensemble de test :", X_test.shape[0], "\n")
# 4. Définir un modèle + pipeline de prétraitement
# Ici : Standardisation des features + Régression logistique
model = make_pipeline(
StandardScaler(),
LogisticRegression(max_iter=1000, random_state=42)
)
# 5. Entraîner le modèle sur l'ensemble d'entraînement
model.fit(X_train, y_train)
# 6. Évaluer sur l'ensemble de validation
y_val_pred = model.predict(X_val)
val_accuracy = accuracy_score(y_val, y_val_pred)
print("Accuracy sur l'ensemble de validation :", round(val_accuracy, 3))
# 7. Évaluer sur l'ensemble de test (performance finale)
y_test_pred = model.predict(X_test)
test_accuracy = accuracy_score(y_test, y_test_pred)
print("Accuracy sur l'ensemble de test :", round(test_accuracy, 3), "\n")
print("Matrice de confusion (test) :")
print(confusion_matrix(y_test, y_test_pred), "\n")
print("Rapport de classification (test) :")
print(classification_report(y_test, y_test_pred, target_names=iris.target_names))
Les explications de cette section étaient-elles claires ?
L'apprentissage profond (Deep Learning, DL) est une sous-catégorie de l'apprentissage machine qui utilise des réseaux de neurones artificiels profonds pour modéliser et résoudre des problèmes complexes. Ces réseaux sont composés de plusieurs couches de neurones interconnectés, permettant au modèle d'apprendre des représentations hiérarchiques des données.
Le DL est particulièrement efficace pour traiter des données non structurées telles que les images, le texte et l'audio, et a conduit à des avancées significatives dans des domaines comme la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale.
L'apprentissage profond a permis des avancées significatives dans divers domaines, notamment :
| Domaine | Exemples |
|---|---|
| Vision par ordinateur | Reconnaissance faciale, détection d'objets |
| Traitement du langage naturel | Traduction automatique, chatbots |
| Génération de contenu | Création d'images, musique, texte |
| Santé | Diagnostic médical, analyse d'images médicales |
Le neurone artificiel est l'unité de base des réseaux de neurones en apprentissage profond. Il reçoit plusieurs entrées, applique des poids à chacune d'elles, additionne le tout avec un biais, puis applique une fonction d'activation pour produire une sortie.
À la base, il est inspiré du fonctionnement d'un neurone biologique :
- Bien que le neurone artificiel s’inspire du fonctionnement du neurone biologique, il ne s’agit que d’une approximation mathématique très simplifiée.
- Les neurones biologiques sont des structures extraordinairement complexes : ils communiquent au moyen de signaux électriques et chimiques, s’adaptent en permanence, possèdent des milliers de connexions (synapses) et fonctionnent selon des principes continu (analogique) plutôt que numérique.
- Certains projets ambitieux, comme le Blue Brain Project, tentent de modéliser le cerveau humain. Mais en pratique, les neurones artificiels utilisés en apprentissage machine restent des abstractions conçues pour résoudre des tâches spécifiques, sans chercher à reproduire la complexité réelle du cerveau.
- En réalité, nous comprenons encore mal le fonctionnement détaillé d’un seul neurone biologique. Alors imaginer modéliser le cerveau humain dans son ensemble — qui compte environ 100 milliards de neurones, interconnectés par 100 trillions de synapses — dépasse largement nos capacités actuelles de simulation et de compréhension.
- Même avec les avancées spectaculaires en intelligence artificielle, la complexité du cerveau humain demeure infiniment supérieure à ce que nos modèles peuvent reproduire.
- Pour aller plus loin, vous pouvez lire Le cerveau, l’univers dans votre tête du neurochirurgien David Fortin — un excellent ouvrage de vulgarisation.
Le quessé?? Le perceptron est l'un des modèles de neurones artificiels les plus simples et les plus fondamentaux en apprentissage machine. Il a été introduit par Frank Rosenblatt en 1958. Le perceptron est conçu pour effectuer des tâches de classification binaire, c'est-à-dire qu'il peut distinguer entre deux classes différentes.
Le perceptron fonctionne en prenant plusieurs entrées pondérées, en les sommant, puis en appliquant une fonction d'activation (généralement une fonction seuil) pour produire une sortie binaire (0 ou 1).
Le code suivant illustre le fonctionnement d'un perceptron simple en Python pour apprendre la fonction logique ET :
# Données d'entraînement (ET logique)
X = [(0,0), (0,1), (1,0), (1,1)]
y = [0, 0, 0, 1]
# Poids initiaux
w = [0.1, -0.2]
b = 0.0
lr = 0.1
# Fonction d'activation (seuil)
def activation(z):
return 1 if z >= 0.5 else 0
# Entraînement
for epoch in range(20):
for (x1, x2), cible in zip(X, y):
z = w[0]*x1 + w[1]*x2 + b
pred = activation(z)
err = cible - pred
# Mise à jour des poids
w[0] += lr * err * x1
w[1] += lr * err * x2
b += lr * err
# Test final
for (x1, x2) in X:
z = w[0]*x1 + w[1]*x2 + b
print((x1, x2), activation(z))
Le perceptron peut être entraîné à l'aide d'un algorithme simple qui ajuste les poids en fonction des erreurs de classification sur un ensemble de données d'entraînement. Cependant, le perceptron a des limitations, notamment son incapacité à résoudre des problèmes non linéaires, ce qui a conduit au développement de réseaux de neurones plus complexes et profonds.
Un réseau de neurones artificiels est une architecture composée de plusieurs couches de neurones interconnectés :
- une couche d’entrée qui reçoit les données (features),
- une ou plusieurs couches cachées qui transforment progressivement les représentations,
- une couche de sortie qui produit la prédiction (classe, probabilité, valeur numérique, etc.).
Chaque neurone applique une combinaison linéaire de ses entrées (poids + biais), puis une fonction d’activation non linéaire. En empilant plusieurs couches, le réseau peut apprendre des représentations hiérarchiques de plus en plus abstraites.
Le schéma ci-dessous illustre un réseau simple avec :
- 3 neurones d’entrée
- 2 couches cachées
- 1 neurone de sortie
Dans un vrai modèle de deep learning, il peut y avoir :
- beaucoup plus de neurones par couche,
- de nombreuses couches cachées (réseaux “profonds”),
- des types de couches spécialisés (convolutions, récurrences, attention, etc.), mais l’idée de base reste la même : propager l’information de gauche à droite en la transformant à chaque couche.
Dans un réseau profond entraîné à reconnaître des animaux dans des images, les couches n’apprennent pas toutes la même chose :
- Les premières couches repèrent surtout des motifs très simples : bords, orientations, contrastes.
- Les couches intermédiaires apprennent des textures et motifs locaux : pelage, motifs de fourrure, contours d’oreilles, etc.
- Les couches plus profondes combinent ces éléments pour reconnaître des parties d’objets : yeux, museau, pattes…
- Les dernières couches construisent une représentation globale de l’animal entier et produisent la classe prédite (chat, chien, oiseau, etc.).
Ce schéma illustre cette montée progressive en abstraction :
Dans un tel modèle de réseau de neurones convolutifs (Convolutional Neural Network, CNN), ces “couches” sont des couches convolutionnelles apprenant automatiquement ces niveaux de représentation, sans que l’on dise explicitement au modèle “voici un bord” ou “voici une patte” : il les découvre à partir des données et se construit sa propre hiérarchie de caractéristiques.
Voici quelques architectures de réseaux de neurones couramment utilisées en apprentissage profond :
| Architecture | Description | Applications |
|---|---|---|
| Réseaux de neurones convolutifs (CNN) | Utilisent des couches convolutionnelles pour extraire des caractéristiques spatiales | Vision par ordinateur, reconnaissance d'images |
| Réseaux de neurones récurrents (RNN) | Conçus pour traiter des séquences de données en utilisant des connexions récurrentes | Traitement du langage naturel, séries temporelles |
| Transformeurs | Utilisent des mécanismes d'attention pour capturer les dépendances à long terme dans les données séquentielles | Traduction automatique, modèles de langage |
| Autoencodeurs | Réseaux non supervisés utilisés pour la réduction de dimensionnalité et la génération de données | Compression de données, génération d'images |
Malgré ses succès, l'apprentissage profond présente plusieurs défis :
- Données massives : Nécessite de grandes quantités de données étiquetées pour un entraînement efficace.
- Coût computationnel : Entraînement de modèles profonds demande des ressources matérielles importantes (GPU/TPU).
- Interprétabilité : Les modèles profonds sont souvent considérés comme des "boîtes noires", rendant difficile la compréhension de leurs décisions.
- Surapprentissage : Risque accru de surapprentissage en raison de la complexité des modèles.
- Biais : Les modèles peuvent apprendre et amplifier les biais présents dans les données d'entraînement.
Voici un exemple d'utilisation de la bibliothèque Keras (incluse dans TensorFlow) pour entraîner un réseau de neurones simple sur le jeu de données MNIST (images de chiffres manuscrits 28×28).
Ce jeu de données est constitué d'environ 60 000 images de chiffres (0 à 9) écrits à la main.
Le but est de construire un modèle capable de reconnaître correctement des chiffres écrits à la main.
L'objectif est de montrer les grandes étapes d'un entraînement en deep learning :
- Charger un jeu de données intégré à Keras
- Prétraiter les données (normalisation, mise en forme)
- Créer un modèle (architecture)
- Compiler le modèle (choix de la fonction de perte, de l’optimiseur, des métriques)
- Entraîner le modèle (
fit) - Évaluer sur un ensemble de test
💡 Cet exemple est surtout illustratif : pour l’exécuter, il faut avoir installé
tensorflow(qui contientkeras), ce qui peut prendre environ 3 minutes à installer via le terminal intégré:
pip install tensorflow
# 1. Importer les bibliothèques nécessaires
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 2. Charger le jeu de données MNIST
# (images de chiffres manuscrits 28x28 en niveaux de gris)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print("Taille x_train :", x_train.shape)
print("Taille y_train :", y_train.shape)
print("Taille x_test :", x_test.shape)
print("Taille y_test :", y_test.shape)
# 3. Prétraitement des données
# - Conversion en float32
# - Normalisation des pixels dans [0, 1]
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
# On réserve une partie de x_train pour la validation
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
print("Après split :")
print("Entraînement :", x_train.shape, y_train.shape)
print("Validation :", x_val.shape, y_val.shape)
print("Test :", x_test.shape, y_test.shape)
# Les images 28x28 sont aplaties en vecteurs de taille 784
x_train = x_train.reshape((-1, 28 * 28))
x_val = x_val.reshape((-1, 28 * 28))
x_test = x_test.reshape((-1, 28 * 28))
# 4. Définir le modèle (réseau de neurones fully-connected)
model = keras.Sequential(
[
layers.Input(shape=(784,)), # 28*28 pixels
layers.Dense(128, activation="relu"), # Couche cachée 1
layers.Dense(64, activation="relu"), # Couche cachée 2
layers.Dense(10, activation="softmax"), # 10 classes (chiffres 0–9)
]
)
# Afficher un résumé du modèle
model.summary()
# 5. Compiler le modèle
# - Optimiseur : Adam
# - Perte : entropie croisée pour labels entiers (sparse_categorical_crossentropy)
# - Métrique : accuracy
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# 6. Entraîner le modèle
history = model.fit(
x_train,
y_train,
epochs=5, # Nombre de passes sur les données d'entraînement
batch_size=32, # Taille des mini-lots
validation_data=(x_val, y_val),
)
# 7. Évaluer la performance sur l'ensemble de test
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"Loss sur le test : {test_loss:.4f}")
print(f"Accuracy sur le test : {test_acc:.4f}")
# 8. Faire quelques prédictions (optionnel)
import numpy as np
samples = x_test[:5]
labels = y_test[:5]
pred_probas = model.predict(samples)
pred_labels = np.argmax(pred_probas, axis=1)
print("Labels réels :", labels)
print("Labels prédits :", pred_labels)
Les explications de cette section étaient-elles claires ?
Derrière chaque requête à un modèle d’IA, il y a :
- des centres de données 🏢 remplis de serveurs et de GPU ;
- une consommation d’électricité ⚡ (souvent produite à partir de combustibles fossiles) ;
- du refroidissement 💧 (eau, climatisation) ;
- et du matériel à fabriquer puis à recycler (métaux, terres rares, déchets électroniques).
Selon l’Agence internationale de l’énergie (AIE), les centres de données consommaient déjà autour de 1,5 % de l’électricité mondiale en 2024, et cette part pourrait doubler d’ici 2030, en grande partie à cause de l’IA. oai_citation:0‡IEA
On peut simplifier l’empreinte écologique de l’IA en trois grandes composantes :
-
Entraînement des modèles
- Entraîner un grand modèle (par ex. un grand modèle de langage) peut consommer des dizaines de GWh d’électricité.
- Certaines estimations pour des modèles de type GPT-3 parlent de centaines de tonnes de CO₂e émises pour un seul entraînement. oai_citation:1‡The Sustainable Agency
- Cela représente l’équivalent de centaines de vols long-courrier ou de la vie entière d’émissions d’une voiture moyenne.
-
Utilisation quotidienne (inférence)
- Une fois le modèle déployé, chaque requête (chat, image, recommandation…) consomme de l’énergie.
- Google estimait déjà qu’environ 60 % de l’énergie liée à l’IA était consommée par l’inférence (usage quotidien), contre 40 % pour l’entraînement. oai_citation:2‡news.climate.columbia.edu
- Avec des millions d’utilisateurs, ces “petites” requêtes s’additionnent.
-
Eau et refroidissement
- Les centres de données utilisent de grandes quantités d’eau pour le refroidissement.
- Une étude estimait par exemple qu’un entraînement de GPT-3 avait nécessité de l’ordre de 700 000 L d’eau douce pour le refroidissement, l’équivalent de la fabrication de centaines de voitures. oai_citation:3‡Earth.Org
Pour visualiser le chemin de l’impact :
Ces chiffres évoluent vite, mais donnent une idée des échelles :
| Aspect | Ordre de grandeur | Source / contexte |
|---|---|---|
| Part de l’électricité mondiale utilisée par les centres de données | ~1,5 % en 2024 | AIE (Energy and AI) oai_citation:4‡IEA |
| Projection pour 2030 | Jusqu’à ~3 % de l’électricité mondiale | AIE, scénarios 2030 oai_citation:5‡IEA |
| Entraînement d’un très grand modèle | centaines de milliers de kg de CO₂e (≈ centaines de vols long-courrier) | études sur GPT-3 et autres grands modèles oai_citation:6‡The Sustainable Agency |
| Eau utilisée pour l’entraînement d’un grand modèle | ~700 000 L pour un entraînement (ordre de grandeur) | étude sur GPT-3 oai_citation:7‡Earth.Org |
🧊 À l’échelle d’un TP en cégep, votre impact est très faible comparé à celui de grands modèles industriels. Mais comprendre ces ordres de grandeur permet de réfléchir à une pratique plus sobre dès maintenant.
Des équipes de recherche et d’ingénierie travaillent à réduire l’empreinte écologique de l’IA, ce qu’on appelle parfois Green AI. oai_citation:8‡ScienceDirect Parmi les stratégies :
-
Modèles plus petits et efficaces
- Utiliser des modèles plus compacts quand c’est possible (au lieu de toujours choisir “le plus gros modèle”).
- Techniques de compression, quantification, distillation pour réduire la taille des modèles. oai_citation:9‡esdst.eu
-
Matériel et infrastructures plus sobres
- Data centers alimentés par des énergies renouvelables (solaire, éolien, hydro).
- Serveurs et GPU plus efficaces sur le plan énergétique.
-
Optimisation des entraînements
- Limiter le nombre d’expériences redondantes.
- Planifier les entraînements aux moments où l’électricité est plus “propre” (forte part de renouvelable). oai_citation:10‡research.google
-
Mesure du carbone
- Utiliser des outils comme CodeCarbon ou autres frameworks pour estimer l’empreinte carbone d’un entraînement.
- Intégrer cette information dans les choix de modèles et d’architectures. oai_citation:11‡InfoQ
À votre échelle (TP en Python, petits modèles, jeux de données modestes), l’impact direct est très faible, mais vous pouvez déjà adopter de bons réflexes :
-
Éviter le gaspillage de calcul
- Ne pas lancer 50 fois le même entraînement “pour rien”.
- Sauvegarder les modèles entraînés au lieu de tout refaire à chaque exécution.
-
Commencer simple
- Tester d’abord des modèles simples (régression, petits arbres, petits réseaux).
- N’augmenter la complexité que si nécessaire.
-
Réutiliser plutôt que tout recréer
- Quand c’est possible, utiliser des modèles pré-entraînés légers ou des bibliothèques optimisées (scikit-learn, etc.).
-
Être curieux·se de la question
- Lorsqu’on vous présente un nouvel outil d’IA, vous pouvez poser la question :
“Et son empreinte écologique, on sait quelque chose là-dessus?”
- C’est déjà une manière de faire évoluer les pratiques.
- Lorsqu’on vous présente un nouvel outil d’IA, vous pouvez poser la question :
L’objectif n’est pas de vous culpabiliser dès maintenant, mais de vous donner des repères : l’IA n’est pas “magique” ni “immatérielle”, elle repose sur des infrastructures bien réelles, avec un coût énergétique et matériel. 🌱
Les explications de cette section étaient-elles claires ?
Scikit-learn est une bibliothèque Python utilisée pour faire de l’apprentissage automatique (machine learning).
Elle permet de créer des modèles capables de détecter des relations dans les données afin de faire des prédictions.
On retrouve principalement trois types d’algorithmes :
- Classification → classer des éléments (ex : ceci est une photo de chat, ceci est une photo de chien)
- Régression → prédire une valeur numérique (ex : combien de Bixi seront empruntés demain)
- Clustering → regrouper des données similaires (ex : identifier des groupes de clients avec des comportements semblables)
🧠 Concepts clés
- Modèle : algorithme qui apprend à partir des données
- Prétraitement des données : préparer les données (normaliser, encoder, nettoyer)
- Évaluation des modèles : mesurer la qualité des prédictions
- Pipeline : enchaîner plusieurs étapes automatiquement
👉 Cette semaine, nous allons nous concentrer sur des modèles simples de régression, en lien avec la visualisation des données.
Nous utiliserons le jeu de données classique Auto MPG (Miles per Gallon) pour explorer la relation entre la consommation d’essence (mpg) et des variables comme le poids (weight) ou le nombre de cylindres (cylinders).
- Ce jeu de données (dataset) est très vintage (années 70-80), mais reste un excellent exemple pédagogique.
- Vous pouvez le télécharger ici : mpg_dataset.csv
🧰 Chargement du jeu de données
import pandas as pd
# Chargement du jeu de données
df = pd.read_csv('mpg_dataset.csv')
# Aperçu
print(df.head())
df.info()
mpg cylinders displacement ... model_year origin name
0 18.0 8 307.0 ... 70 usa chevrolet chevelle malibu
1 15.0 8 350.0 ... 70 usa buick skylark 320
2 18.0 8 318.0 ... 70 usa plymouth satellite
3 16.0 8 304.0 ... 70 usa amc rebel sst
4 17.0 8 302.0 ... 70 usa ford torino
[5 rows x 9 columns]
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
Ce jeu de données contient 398 entrées (voitures) avec les 9 colonnes suivantes :
mpg: consommation en miles par galloncylinders: nombre de cylindresdisplacement: cylindrée en pouces cubeshorsepower: puissance en chevauxweight: poids en livresacceleration: temps d’accélération de 0 à 60 mphmodel_year: année du modèleorigin: pays d’origine (usa, europe, japan)name: nom du modèle
Ce qui nous intéresse ici, c’est de voir comment certaines caractéristiques (ex. poids, cylindres) influencent la consommation (mpg, première colonne).
Regroupons les voitures par nombre de cylindres et calculons la moyenne de consommation pour chaque groupe :
# Moyenne de la consommation par nombre de cylindres
print(df.groupby("cylinders")["mpg"].mean())
cylinders
3 20.550000
4 29.286765
5 27.366667
6 19.985714
8 14.963107
Name: mpg, dtype: float64
💡 On observe une relation inverse : à l'exception des petits 3-cylindres, on dirait que plus il y a de cylindres, plus la mesure de consommation (mpg) diminue. 🤔
C'est plutôt logique : plus une voiture a de cylindres, plus elle consomme d’essence (donc moins elle parcourt de miles par gallon).
Mais c'est un peu mélangeant, car on est plutôt habitué à penser à l'envers, soit en litres consommés aux 100 km (L/100km), où une consommation plus faible est donc meilleure.
👉 Nous allons donc créer une nouvelle colonne l_par_100km pour convertir mpg en litres aux 100 km :
# Conversion mpg -> L/100km
df["l_par_100km"] = 235.214583 / df["mpg"]
Refaisons le même calcul avec cette nouvelle colonne :
print(df.groupby("cylinders")["l_par_100km"].mean())
cylinders
3 11.578018
4 8.333277
5 9.103094
6 12.106109
8 16.235661
Name: l_par_100km, dtype: float64
Visualisons maintenant la relation entre le poids (weight) et la consommation (l_par_100km) avec un graphique de dispersion (scatter plot) :
# Visualisation simple
import matplotlib.pyplot as plt
plt.scatter(df["weight"], df["l_par_100km"], alpha=0.6)
plt.xlabel("Poids du véhicule (lbs)")
plt.ylabel("Consommation d'essence (L/100km)")
plt.title("Consommation d'essence en fonction du poids du véhicule")
plt.show()
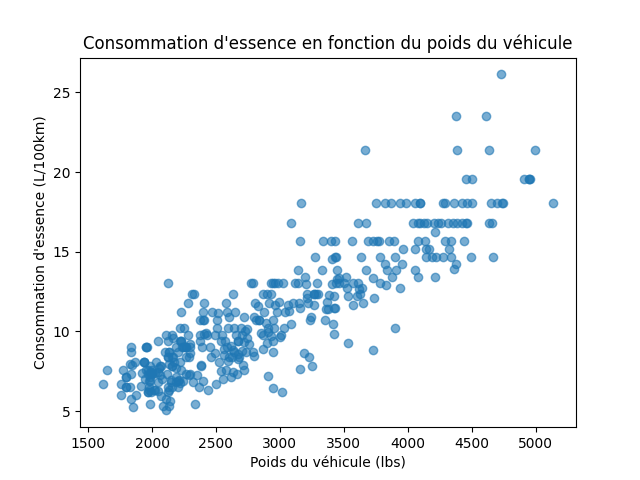
💬 On observe une tendance claire : plus le poids du véhicule augmente, plus la consommation en litres aux 100 km augmente également. Cela confirme notre intuition que les voitures plus lourdes consomment plus d’essence.
Nous allons modéliser cette relation avec une régression linéaire (LinearRegression).
Préparons d'abord les données :
# Suppression des lignes contenant des valeurs manquantes
# (on regarde seulement les colonnes utilisées : l_par_100km et weight)
df = df.dropna(subset=["l_par_100km", "weight"])
# Préparation des variables
X = df[["weight"]] # variables explicatives (celles utilisées pour prédire y)
y = df["l_par_100km"] # variable cible (celle que l'on veut prédire)
Il est très important de bien comprendre ici la structure de X et y :
Xest un DataFrame à 2 dimensions (double[et double]) même si une seule colonne : il doit toujours être en 2D pour Scikit-learn.yest une Series (1D) contenant les valeurs cibles.
Ici :
Xest une matrice 2D de dimensions (n_samples, n_features) oùn_samplesest le nombre de voitures etn_featuresest 1 (le poids).yest un vecteur 1D de longueurn_samplescontenant les valeurs de consommation (l_par_100km).
Plus précisément, comme on a 398 voitures, X aura une forme (398, 1) et y aura une forme (398,) :
print(X)
weight
0 3504
1 3693
2 3436
3 3433
4 3449
.. ...
393 2790
394 2130
395 2295
396 2625
397 2720
[398 rows x 1 columns]
print(y)
0 13.067477
1 15.680972
2 13.067477
3 14.700911
4 13.836152
...
393 8.711651
394 5.345786
395 7.350456
396 8.400521
397 7.587567
Name: l_par_100km, Length: 398, dtype: float64
Entraînons maintenant le modèle de régression linéaire :
from sklearn.linear_model import LinearRegression
# On crée un modèle linéaire :
model = LinearRegression()
# Le modèle va essayer de trouver la "meilleure droite" qui représente la relation entre X et y.
# 👉 On "entraîne" le modèle :
model = model.fit(X, y)
# ⚠️ ici, le score est calculé sur les données d'entraînement :
print("Score R² :", model.score(X, y))
print("Coefficient :", model.coef_[0])
print("Intercept :", model.intercept_)
Score R² : 0.7836118983544517
Coefficient : 0.0040789144329788085
Intercept : -0.9030520509041988
-
Un score R² de 0.78 indique que le modèle explique environ 78% de la variance observée dans la consommation (
l_par_100km) en fonction du poids- R² indique que le modèle explique bien la relation observée (très bon).
- Un score R² = 1 : Le modèle explique parfaitement la variance des données (Parfait)
- Un score 0.7 ≤ R² < 1 : Le modèle explique bien la variance, mais pas parfaitement (Très bon)
- Un score 0.5 ≤ R² < 0.7 : Le modèle explique une partie significative de la variance (Acceptable)
- Un score 0.3 ≤ R² < 0.5 : Le modèle a une faible capacité explicative (Médiocre)
- Un score 0 ≤ R² < 0.3 : Le modèle explique très peu de la variance (Faible)
- Un score R² = 0 : Le modèle n'explique rien du tout (Inutile)
- Un score R² < 0 : Le modèle est pire qu'une simple moyenne (régression non pertinente) (Mauvais)
-
Le coefficient positif (0.00408) confirme que la relation est directe : plus le poids augmente, plus la consommation (L/100km) augmente :
- Coefficient positif : la variable cible augmente quand la variable explicative augmente.
- Coefficient négatif : la variable cible diminue quand la variable explicative augmente.
- Coefficient proche de zéro : la variable explicative a peu ou pas d’effet.
-
La relation entre le poids et la consommation peut donc être modélisée par la formule de la droite de régression suivante :
(où 0.00408 est la valeur du coefficient et -0.903 est la valeur intercept)
La méthode model.predict() permet d'obtenir les valeurs cibles prédites par le modèle (à l'aide de la formule).
# On calcule les valeurs prédites par le modèle pour chaque poids
y_pred = model.predict(X)
plt.scatter(X, y, label="Données réelles", alpha=0.6)
# On ajoute la droite de régression :
plt.plot(X, y_pred, color="red", label="Régression linéaire")
plt.xlabel("Poids du véhicule (lbs)")
plt.ylabel("Consommation d'essence (L/100km)")
plt.title("Régression linéaire : Poids vs Consommation")
plt.legend()
plt.show()
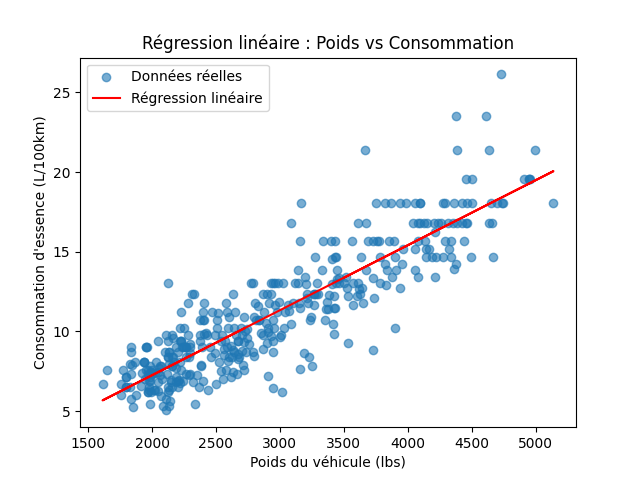
💬 On obtient une droite de tendance montrant clairement la relation linéaire entre le poids et la consommation :
- Les points bleus représentent les données réelles (poids vs consommation).
- La ligne rouge est la droite de régression linéaire ajustée par le modèle.
Colorons les points en fonction du nombre de cylindres pour voir si on peut observer une tendance supplémentaire :
# pour chaque nombre de cylindres :
for cyl in [8, 6, 5, 4, 3]:
# on crée un dataframe filtré pour ce nombre de cylindres :
subset = df[df["cylinders"] == cyl]
# puis on trace les points correspondants :
plt.scatter(subset["weight"], subset["l_par_100km"], alpha=0.6, label=f"{cyl} cylindres")
plt.xlabel("Poids du véhicule (lbs)")
plt.ylabel("Consommation d'essence (L/100km)")
plt.title("Consommation en fonction du poids selon le nombre de cylindres")
plt.legend()
plt.show()
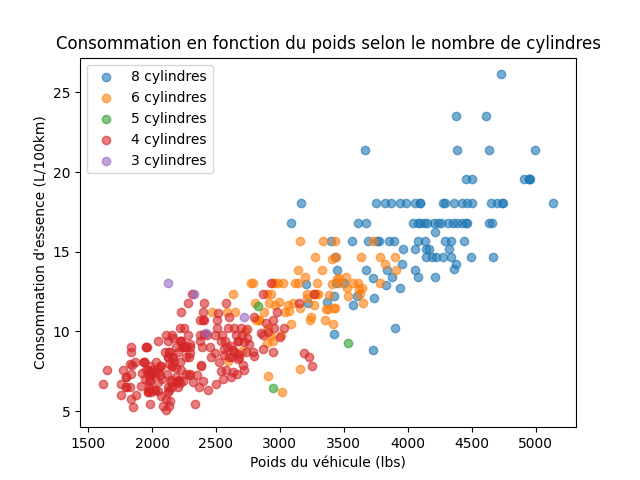
💬 On observe que les voitures avec plus de cylindres (ex. 8 cylindres) ont tendance à être plus lourdes et à consommer plus d’essence, ce qui confirme notre analyse précédente.
On peut facilement ajouter d’autres variables (ex. nombre de cylindres, puissance) :
# Suppression des lignes contenant des valeurs manquantes
# (seulement pour les colonnes utilisées dans le modèle)
df = df.dropna(subset=["l_par_100km", "weight", "cylinders", "horsepower"])
# Préparation des variables :
# X → variables explicatives (plusieurs colonnes → modèle multiple)
# y → variable cible (ce qu'on veut prédire)
X = df[["weight", "cylinders", "horsepower"]]
y = df["l_par_100km"]
# On crée un modèle linéaire :
model = LinearRegression()
# Le modèle va essayer de trouver la "meilleure combinaison" de ces variables pour prédire y.
# 👉 On "entraîne" le modèle :
model.fit(X, y)
# ⚠️ ici, le score est calculé sur les données d'entraînement :
print("Score R² :", model.score(X, y))
print("Coefficients :", model.coef_)
print("Intercept :", model.intercept_)
Coefficients : [0.00229432 0.2757425 0.03284566]
Score R² : 0.8176921365228299
Intercept : -0.5232093212414135
- Le score R² a augmenté à 0.82, indiquant que l’ajout de ces deux variables supplémentaires améliore la capacité du modèle à expliquer la variance de la consommation.
- La relation reste positive pour le poids et le nombre de cylindres, et la puissance a aussi un effet positif sur la consommation.
- La formule de la régression multiple est donc :
(où 0.00229, 0.2757 et 0.03285 sont les valeurs des coefficients des variables explicatives et -0.5232 est la valeur intercept)
📁 Créez un fichier r11_regression_lineaire.py pour votre réponse.
Utilisez 🤖 Scikit-learn pour créer un modèle de régression linéaire simple qui prédit la consommation l_par_100km en fonction de la puissance (horsepower).
Affichez le score R², le coefficient et l'intercept du modèle :
Score R² : 0.7306976406434581
Coefficient : 0.08691820578815233
Intercept : 2.168240692150743
Ensuite, générez ce graphique de dispersion avec la droite de régression linéaire :
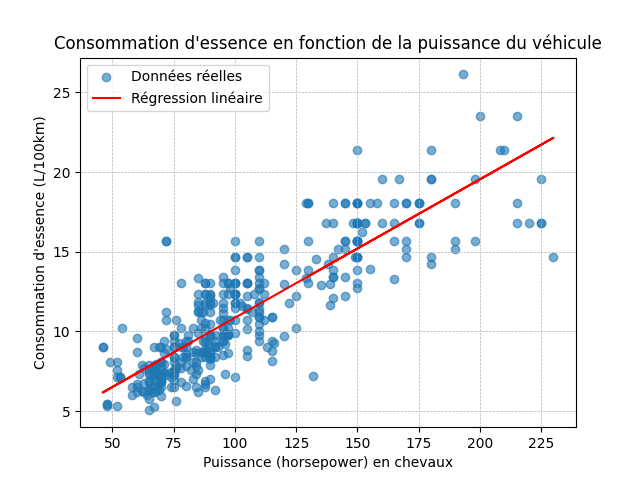
Les explications de cette section étaient-elles claires ?